主要是开发和运维领域的介绍,尚不成体系,待整理TODO
Dev|Ops
此Dev|Ops非彼DevOps,很明显有墙!
- 1: 机器学习的语言之争
- 2: 监控之我见
- 3: Github开源项目的正确贡献姿势
- 4: Golang开发-glog日志库
- 5: VSCode-开发已有的java项目
- 6: MongoDB之初见
- 7: Openldap之拨云见日
- 8: Casbin的权限管理解读
- 9: Windows Terminal终端入坑指南
- 10: Golang单仓monorepo协作的设计与实践
- 11: TiDB分布式数据库
- 11.1: TiDB初体验
- 12: 在AI时代该如何学习Java
- 12.1: Go转Java万字总结, 要跨越哪些思维鸿沟
- 12.2: AI时代下,Java该如何起手项目开发
- 12.3: Goper直接撸java代码,真是操碎了心,tips总结①
1 - 机器学习的语言之争
机器学习的语言之争(译文).
原文:Python, Machine Learning, and Language Wars - A Highly Subjective Point of View
噢,天呀,那些主观有针对性的,自以为标题党的文章的另一个?是哒!为什么我还要不厌其烦的写下来呢?嗯,这里是来自于我的前教授的最琐碎但又改变生活的洞察和世俗的智慧之一,它已经成为了我的口头禅了:“如果你必须做这个任务超过三次以上,那么只要写一个脚本,然后对其自动化。”
现在,你或许已经开始琢磨这个博客了。我已经超过半年没写什么东西了!好吧,沉迷在社交网络平台除外,那不是真的:我写了一些东西 —— 准确来说,约400页。最近,对我来说,这真的已经是一次旅程了。而对于经常被问道的问题“为什么你选择Python来进行机器学习?”,我猜,是时候来写_我的脚本_了。
在下面的段落中,我真的不打算告诉你为什么_你_或者其他人应该使用Python。老实说,我真心讨厌那类问题:“哪个最好?”(这里,用“编程语言、文本编辑器、IDE、操作系统、计算机制造商”替换掉)。这实在是扯淡。虽然有时它挺有意思的,但是我建议你节省下关于这个问题的时间,用来在下班后跟朋友或者同事偶尔喝喝啤酒或咖啡。
目录
- 对于一个复杂问题的简短回答
- 我最喜欢的Python工具是什么?
- 我对MATLAB是怎么看的?
- Julia真棒……理论上!
- R实在没啥错
- Perl发生了什么?
- 其他观点
- Python是一个正在死掉的语言吗?
- 总结
- 反馈和观点
对于一个复杂问题的简短回答
或许我应该从一个简短的回答开始。欢迎你停止阅读这段后面的文章,因为它真的解决掉这个问题了。我是一个科学家,我喜欢完成我的工作。我喜欢有一个环境,在那里我可以快速原型,并记下我的模型和想法。我需要解决非常特殊的问题。我分析给定的数据集以得出结论。这对我来说是最重要的:我怎样才能最多产的完成我的工作呢?“多产”这里意味着什么?好吧,我通常只进行一次分析 (不同的想法测试和调试除外); 我不需要重复地24/7地运行一段特定的代码,我并不是在为最终用户开发软件应用或web应用。当我_量化y_ “多产”时,我从字面上评估(1) 把想法以代码的形式写下来所花费的时间,(2) 调试的时间和 (3) 执行的时间之和。对我来说,“最多产”意味着“获得结果需要花费多少时间?” 现在,这么多年来,我发现,Python就是为我而生的。并非总是如此,但很多时候是这样。正如生活中的其他东西一样,Python并不是“银弹”,它并非总是每一个问题的“最佳”解决方案。然而,如果你跨常见和不那么常见的问题任务来比较编程语言的话,它已经非常接近(最佳解决方案)了;Python可能是最通用,最有能力的全才。

(来源: https://xkcd.com/974/)
请记住:“过早的优化是一切罪恶的根源” (Donald Knuth)。如果你是那种想要从机器学习和数据科学划分中中优化下一个颠覆性高频交易模型的软件工程团队中的一员,那么Python可能不适合你 (但或许它是数据科学团队的语言选择,所以学习如何读懂它仍然有用)。因此,我的一个小小的忠告是,当你选择一门语言时,评估你每天的问题任务和需求。“如果你只有一把锤子,那么一切开始看起来都像一个钉子” – 你聪明得不会掉入这个陷阱!然而,记住,有一个平衡点。在有些场景下,即使螺丝刀可能是“更漂亮的”解决方法,锤子可能还是最好的选择。再次,这归结为生产力。
让我从个人经历中挑个例子来说说。 关于一个非常问题相关的假设,我需要开发一堆新颖的算法来“筛选”1千5百万个小的化合物。我完全是一个计算型人,但我和进行非计算性实验(我们称它们为“湿实验室”实验)的生物学家一起合作。目标是缩小它到一个包含100个潜在化合物的列表,这样他们可以在实验室里测试它们。提醒是,他们需要快速获得结果,因为他们仅有有限的实际来做实验。相信我,时间真的是“有限的”:在必须收集结果之前,我们刚让我们的补助金申请受理和研究得到资助 (我们的合作者对某种特定的只知春季产卵的幼虫做实验)。因此,我开始想“我要怎样尽可能快的把结果给他们?” 嗯,我懂C++和FORTRAN,如果我在各个语言中实现那些算法,那么与Python实现相比,执行“筛选”运行也许会更快些。这更多是一种有根据的猜测,我真的不知道实质上是否会更快。但有一件事我可以肯定:如果我开始用Python写代码,那么我可以让它在几天内运行 – 或许让对应的C++版本能够跑起来需要花一周的时间。以后,我会操心一个更有效的实现。在那一刻,重要的是,把那些结果拿给我的合作者 – “过早的优化是一切罪恶的根源。” 边注:相同的思路运用到数据存储解决方案。这里,我只是使用SQLite。CSV没有多大意义,因为我必须重复地注释和检索某些分子。我当然不想每次想要查看一个分子或者操作它的时候,都要全过程扫描或重写一个CSV – 在处理内存容量预留的问题。也许用MySQL会更好,但是出于上面提到的原因,我想快速地完成这项工作,并建立一个额外的SQL服务器……没时间做它了,用SQLite来完成这项工作挺好的。

(来源: https://xkcd.com/1319/)
结论:**选择满足_你的_需求的那个语言!**不过,这里有一个小小的告诫!初学者在学习一门语言之前怎么能知道它的优势和缺点,程序员应该怎么知道这门语言对她来说会是有用的呢?这就是我会做的事:只要在谷歌和GitHub上搜索那些与你最常见的问题任务有关的特别的应用和解决方法。你不需要阅读和了解代码。只需要看看最终产品,另外,不要犹豫问别人。不要只是询问一般“最好的”编程语言,而是具体点,描述你的目标以及为什么你想要学习如何编程。如果你想为MacOS X开发应用,那么你可能会想要看看Objective C和Swift,如果你想在Android上开发,那么你可能会对Java更感兴趣,以此类推。
我最喜欢的Python工具是什么?
如果你感兴趣,那些是我最喜欢并且最常使用的Python“工具”,每天,我都会使用它们中的大部分。
- NumPy: 我处理线性代数阵列结构和量化公式最喜欢的库;由SciPy增强。
- Theano: 为机器学习算法减负,并将计算分布到我的GPU内核中。
- scikit-learn: 用于每日、更基本的机器学习任务的最方便的API。
- matplotlib: 当涉及到画图时,这是我所选择的库。有时,我还使用seaborn来绘制特殊的图,例如,热图超级棒!
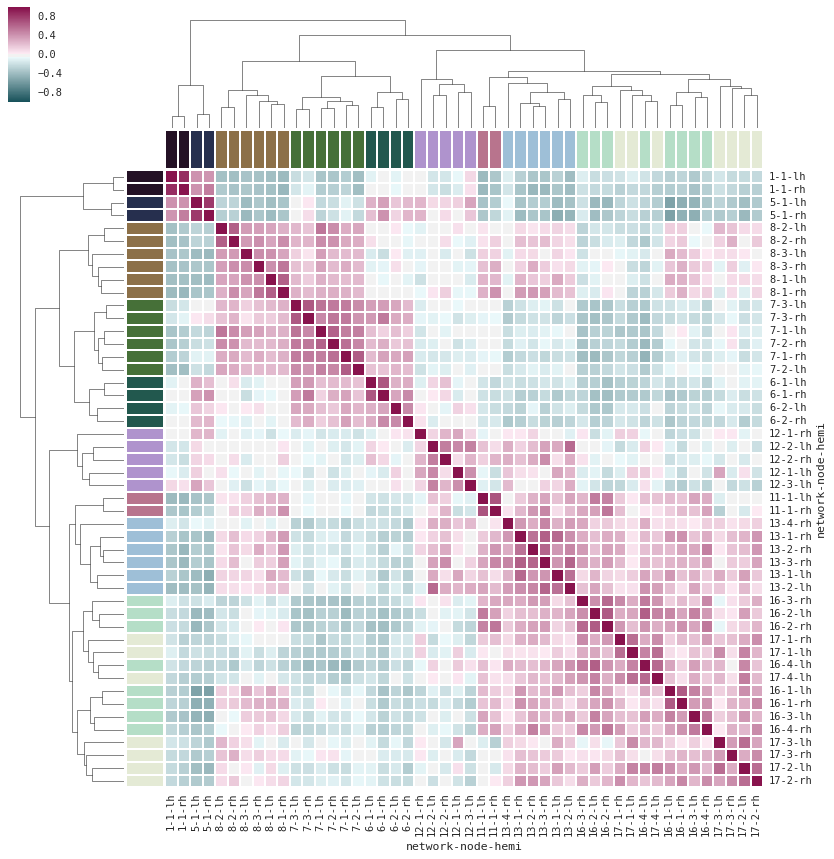
(来源: http://stanford.edu/~mwaskom/software/seaborn/examples/structured_heatmap.html)
- Flask (Django): 难得,我想要将一个想法转换成一个web应用。这里,Flask非常方便!
- SymPy: 对于符号数学,对我来说,它取代了WolframAlpha。
- pandas: 处理相当小的数据集,大多数来自于CSV文件。
- sqlite3:注释和查询“中型”数据集。
- IPython notebooks: 我还能说什么呢?我90%的研究发生在IPython notebooks。它只是一个让所有的东西都放在一个地方的好环境:想法、代码、注释、LaTeX方程、插图、图表、输出……
注意,IPython项目最近演变成了Jupyter项目。现在,你不止可以使用Jupyter notebook环境到Python上,还可以是R, Julia, 等等。
我对MATLAB是怎么看的?
几年前,我想当常用MATLAB (/Octave);大多数的计算机科学数据科学课都是用MATLAB。我真的觉得这对于原型真的一点儿都不是一个糟糕的环境!由于它的设计充分考虑了线性代数 (用于MATrix LABoratory的MATLAB),当涉及到实现机器学习算法时,比之Python/NumPy,MATLAB让人感觉更多点“自然” —— 好啦,为了公平起见,1-indexed编程语言对我们程序员来说,可能看起来有点奇怪。但是,记住,MATLAB带有一个大的价格标签,我认为它真正慢慢地淡出学术界以及工业界。此外,毕竟,我是开源粉 ;)。另外,与其他“生产性”的语言相比,它的性能也并不是那么的引人注目。看看下面的标准:
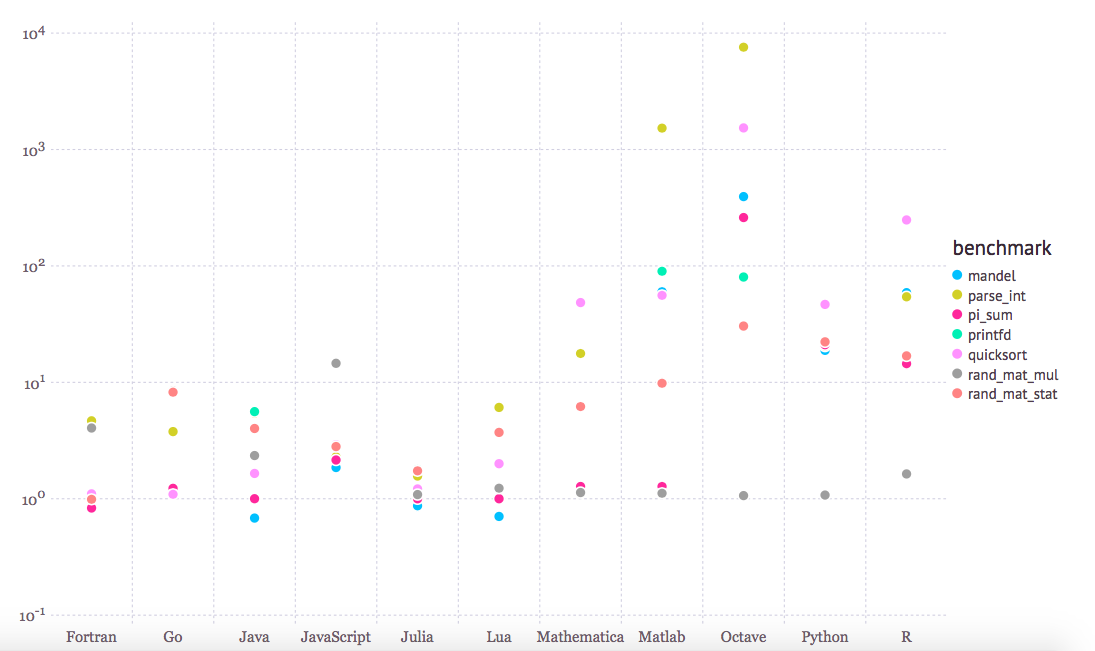
(相对于C的基准次数 —— 越小越好,C的性能 = 1.0; 来源: http://julialang.org/benchmarks/)
然而,我们不应忘记,对于Python,也有这样整洁的Theano库。在2010年,Theano的开发者报道,当代码运行在CPU时,它比NumPy快1.8倍,而如果Theano针对GPU,那么它甚至比NumPy快11倍 (J. Bergstra, O. Breuleux, F. Bastien, P. Lamblin, R. Pascanu, G. Desjardins, J. Turian, D. Warde-Farley, 和Y. Bengio. Theano: Python中的的一个CPU和GPU运算编译器。在Proc. 9th Python in Science Conf, 第1–7页,2010年。)。现在,记住,这个Theano基准是来自2010年,而多年来,Theano得到了显著的改善,现代显卡的功能也是。
我了解到,很多希腊人相信毕达哥拉斯所说的,所有的东西都是从数字生成的。这个断言带来了一个难题:不存在的东西怎么可以甚至设想生成?- Theano of Croton (哲学家,公元前6世纪)
PS: 如果你不喜欢NumPy的dot方法,那么敬请期待即将到来的Python 3.5 – 对于矩阵乘法,我们将获得一个中缀运算符,耶!
“手动的”矩阵矩阵乘法 (我的意思是,无需NumPy的帮助,而BLAS或者LAPACK看起来繁琐且非常低效)。
[[1, 2], [[5, 6], [[1 * 5 + 2 * 7, 1 * 6 + 2 * 8],
[3, 4]] x [7, 8]] = [3 * 5 + 4 * 7, 3 * 6 + 4 * 8]]
如果我们有线性代数和经过优化的库来处理它,谁还会想使用嵌套的for循环来实现这个表达式!?
>>> X = numpy.array()
>>> W = numpy.array()
>>> X.dot(W)
[[19, 22],
[43, 50]]
现在,如果这个dot产品对你来说并无吸引力,那么这是它将会在Python 3.5中的样子:
>>> X @ W
[[19, 22],
[43, 50]]
老实说,我不得不承认,我并不一定是“@”符号作为矩阵操作符的一个大粉丝。然而,我真的长时间苦苦想了这个问题,没法找到更好的“未使用的”符号了。如果你有更好的想法,请让我知道,我真的很好奇!
Julia真棒……理论上!
我认为Julia是一个伟大的语言,并且我会将其推荐给那些开始编程和机器学习的人。虽然,我不确定是否真的应该这样做。为什么呢?要把自己交给这个编程语言,是有点悲伤矛盾的。使用Julia,我们无法肯定在接下来的几年内,它是否会变得够“流行”。等等,“流行性”跟一门编程语言有多棒多有用有啥关系?让我告诉你。窘境是,最有用的语言不一定是设计良好的,但一定是流行的。为什么?
- 已经有大量的(大多数是免费的)库以供你使用,这样一来,你可以对你的时间尽其所用,而无需重新发明轮子。
- 在线查找帮助、教程和样例容易得多。
- 更频繁的语言改善、更新和补丁,会让它“甚至更好”。
- 对协作更友好,并且在团队中工作更简单。
- 更多的人会从你的代码中受益 (例如,如果你决定将其分享到GitHub上)。
就个人而言,我爱Julia本身。它完美的匹配了我的个人兴趣。虽然,我使用Python;主要是因为已经有了那么多超级棒的东西在那里了,这使得它格外得心应手。Python社区一切安好,而我相信在(至少)下一个5到10年内,它还会存在并蓬勃发展。但是对于Julia,我并没那么肯定。我喜欢设计,我觉得这很棒。尽管如此,如果它并不流行,那么我无法分辨它是“面向未来的”。如果在几年内发展停止了呢?我会对那些在这点上将“死”的东西进行投资。然而,如果每个人都这样想,那么新语言就永远没戏了。
R实在没啥错
嗯,我猜我曾经是一个R人,这并不是什么大秘密。甚至我还写过一本关于它的书 (好吧,准确来讲,实际上是关于R中的热图(Heat maps in R)。注意,这是在几年前,在ggplot2是个事之前。没有真正令人信服的理由让你去看看 —— 我指的是这本书。不过,如果你无法抗拒要看看的话,这是免费的、5分钟就可读完的简短版本)。我同意,有点扯远了。所以,回到讨论:R怎么了?我觉得它完全没有不好的地方。我的意思是,毕竟,对于“数据科学”,R是非常强大的,并且完全可以胜任且“大众化”的语言!不久前,甚至微软也开始非常非常感兴趣:Microsoft收购Revolution Analytics,一家用于统计计算和预测分析的开源R编程语言服务商业提供商。
所以,我可以如何总结下对于R的感受呢?我不大确定这句话出自何处 —— 我在前段时间从某处某人那里看到的 —— 但它很好的解释了R和Python之间的区别:“R是统计学家为了自己开发的一门编程语言;而Python是计算机科学家开发的,程序员可以用它来应用统计技术。”该消息的部分是,R和Python都同样能够用于“数据科学”任务,然而,Python语法对我来说,只是感觉更自然 —— 这是个人品味问题。
我只想提出,Theano和在GPU上计算是Python的一个大增益,但我看到R也完全可以:GPU和R上的并行编程。我知道接下来你想问什么:“好吧,那么要是把我当模型编程一个漂亮_闪亮_的web应用又如何?我打赌,这是你没法在R中做的事!” 抱歉,但是你输了;看看Shiny by RStudio,一个R语言的web应用框架。你明白我的意思吗?这里没有赢家。可能永远都不会有。
把我最喜欢的Python引述中的一个从其原有语境中拿出来:“这里,我们都是大人” —— 不要在把我们的时间浪费在语言之争上了。选择那个“适合”你的语言。当涉及到就业市场上的观点:这里也没有对错。我不认为要聘请你为“数据科学家”的公司真的会计较你最喜欢的工具箱 —— 毕竟,编程语言只是“工具”。而最重要的技能是像“数据科学家”一样思考,问正确的问题,能够解决问题。难的是数学和机器学习理论,新的编程语言是可以很容易学到的。试想一下,你学会了如何挥舞锤子来把钉子敲进去,而从不同的制造商那里挑一把锤子能有多难?但如果你仍然感兴趣,例如看看TIOBE Index,_一个_编程语言流行性的估量:
(来源: http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html)
但是,如果我们看看来自Spectrum IEEE的2015年十大编程语言,那么会发现,R语言正在快速攀升(左列:2015,右列:2014)。
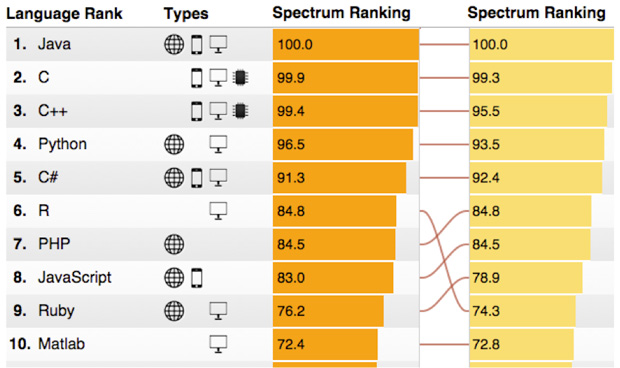
(来源: http://spectrum.ieee.org/computing/software/the-2015-top-ten-programming-languages)
我想你了解了。Python和R,不再有什么真正打的区别了。此外,当你在选择使用哪个语言的时候,你不应该担心工作计划。
Perl发生了什么?
Perl是在我早起职业生涯中选取的第一门语言(当然,除了高中时使用的Basic, Pascal, 和Delphi)。在我还是德国的一个大学生的时候,我上了一门Perl编程课。那时,我真心喜欢它,但是,嘿,在这点上,我确实没有什么好对其进行比较的。就个人而言,我只知道少数几个积极使用Perl为每天写脚本。虽然,我认为在生物信息学领域这仍然相当普遍!? 不管怎么说,让我们保持这部分简短,让它安息:““Perl死了。Perl万岁。”
其他观点
还有许多其他语言可以用于机器学习,例如,Ruby (Thoughtful Machine Learning: A Test-Driven Approach), Java (Java-ML), Scala(Breeze), Lua(Torch), 等等。然而,除了我多年前参与的一个Java类,或者PySpark, 这一用于Spark的Python API,它是用Scala写的,我真的没有使用那些语言的丰富经验,因此不知道该说些什么好。
Python是一个正在死掉的语言吗?
这是一个合法的问题,最近它在Quora出现了,如果你想听听关于这个的一些其他不错的观点,那么看看这个问题支线。不过,如果你想听听我的观点,我会说,不,它不是。为什么?好吧,Python是一门“相当”古老的语言 —— 它的第一个版本是在90年代初的某个时候 (我们可以从1991年开始算起),它像每一个编程语言一样,不得不做出某些选择和妥协。每一个编程语言都有它自己的怪癖,而更现代的语言趋向于从过去的错误中学习,这是件好事 (顺便说一下,R是在Python之后不久发布的:1995)。 Python远不“完美”,而像其他每个语言一样,它有自己的缺点。作为一个核心Python用户,我必须提一下,GIL (Global Interpreter Lock,全局解释锁)是让我最苦恼的东西 —— 但是请注意,有一个多进程和多线程模块,因此它实际上并非是一种限制,而是某些上下文中的小小“不便”。
对于一个编程语言“多棒”并无可以量化的度量,它真正取决于你在找寻什么。你想要问的问题是:“我想要实现什么,哪一个是实现它的最好的工具” —— “如果你只有一把锤子,那么一切开始看起来都像一个钉子。”再次说到锤子和钉子,Python是非常灵活的,我每天大部分的研究都是通过Python,使用强大的scikit-learn机器学习库 —— 用于数据改写的pandas,用户可视化的matplotlib/seaborn,以及用以跟踪所有这些东西的IPython notebooks —— 来完成的。
总结
好啦,这是对于一个看似很简单的问题的一个相当长的答案。相信我,我可以花几小时或几天继续写下去。但为嘛要把事情搞复杂呢?让我们总结一下:

(来源: https://xkcd.com/353/)
反馈和观点
我想要跟你分享关于这篇文章的很多很好的意见。记住,“一句忠告”有所偏颇是自然的;你或许发现了额,我的偏见是非常喜欢Python —— 抱歉啦,但这就是我!我相信,听取其他人的想法也是非常有用的!特别是当你是“数据科学”、机器学习和编程领域的新手的时候。话虽如此,请继续,看看下面的那些带干货的评论!
Python
- hackernews上的rm999:
为了把我的数据管道(从数据源一直到生产模型和前端/可视化)弄到一块,大概一年前,我从大多使用R切换到大多使用Python。这对我能够做的事或者我当生产力并无实际影响,除了我在使用任何语言的前几年中需要对其进行额外的谷歌。我选择Python的主要原因是单纯的实用:这是一个我团队之外的人会尊重和使用的语言。这使得我更容易以许多不同的方法进行协作:与其他团队共享工具,转移代码的所有权,在我需要的时候获得帮助,等等等等。在一些公司,数据科学有“设计一些东西,然后将其抛出墙外让其他人处理”这种美誉。根据我的经验,R只是加深了这种美誉。这太糟糕了,它真的能把它所做的事情做得很好。
- hackernews上的DrNuke:
我喜欢文章中的黑客方法:工具仅仅是做一些有价值的事情的工具,而不是目标本身。如今,因为数据科学爆炸以及快速与非专业人员进行交互的需要,所以,Python生态是正确的时候的正确的工具。
- hackernews上的zzleeper:
非常有意思的文章。我觉得很多数值Pythonistas都处在相同的境地:他们容忍大多数语言,但发现R的语法有点不自然,当试图超越纯矩阵的东西时Matlab有所不足,并都在观望Julia是否会崛起 (在我看来,似乎是会的)
- reddit上的JanneJM:
关键是有足够高品质的库。我知道的许多人,包括我,并不是真的对Python很感兴趣。我们使用Numpy, Scipy, Matplotlib, Pandas等等等等。Python只是来凑凑热闹。要是这些库出现在Ruby / Perl / Lua,那么它们就是我们今天会使用的语言。
Perl
- hackernews上的leni536:
“然而,我认为Perl在生物信息学领域还是相当常见的!?”这是事实 —— 许多生物信息学每天的任务都或多或少有纯文本分析[1],而Perl在解析文本和快速使用正则表达式方面有过人之处。“我”这一代的生物信息学家(20–30)使用Python进行数据清理和分析,有时是因为绘图更好,语言更容易上手,它在高校中较为普遍,或者其他原因 —— 比我这一代年长的人们通常使用P
R
- hackernews上的geomark:
我刚完成了Coursera数据科学之路,这让我从一个完全的R新手变得至少有点精通了。之前我用Python来进行相当多的web编程,起初,除了它统计编程的能力,我并不喜欢R。但最近,我发现了一些不错的R包,它们能让那些我通常会用Python做的事情用R来做变得愉悦。就像我最近发现的用于爬取网页的rvest包。用R进行数据可视化似乎优得多,除非我想念Python中的某些东西(极有可能)。并且提供一个漂亮的统计数据应用是很容易用shiny或者RStudio Presenter做到的。但R真的没法扩展到一个大型生产应用,不是吗?因此,我觉得我需要同时用Python 和R。新增:这是一个不错的列表。谢谢。另外,在文章中,他说Python语法感觉更自然,这也是我所觉得的。但后来我开始使用R中诸如magrittr和dplyr这种包,它们给你像管道一样不错的东西,因此那种感觉开始消退了。
- hackernews上的Adam_O
从一个学生的角度来看,大多数不错的在线分析/数据分析/统计课程都使用R,从医在学习材料的时候,很难摆脱它。一旦你获取了基础概念,那么转到Python应该不难。虽然,我想大多数的人仍然更喜欢用ggplot2进行可视化。每当我使用R的时候,我觉得自己像是一个统计学家,我可以感觉到从这门语言从散发出来的“冷严谨”。但最后,我觉得同时使用这两门语言是有利的。
MATLAB/Octave
- hackernews上的sampo
Andrew Ng在Coursera的机器学习课上说,根据他的经验,用Octave/Matlab完成课程作业的学生比用Python完成的快。但是是的,课程的关键是实现和玩转小数值算法,而该博客是关于那些主要调用Python中已有的机器学习库的人。
- hackernews上的misiti3780
Octave/Matlab是“不错”,但是尝试将其集成到一个生产web应用上还需要点好运气。既然你无法真正做到这点 —— 那么避免使用它们,除非你对实现相同的算法两次并无意见。Matlab license还要花钱买,而工具箱还需要花额外的钱。R是有用的,因为长时间以来它一直有很多资源,并且统计信息社区大部分都在使用它。它还有许多尚未移植到其他语言的有用的库 (ggmap!!!)。但你仍然还是要面对相同的问题,也就是说你没法将R集成到生产WEB应用上。我非常确定,Hadoop之流不支持R, Octave, 或者Matlab。
- hackernews上的thanatropism
这里少了一件事:Matlab的语法其实是非常接近现代Fortran的。我至少通过添加类型/常规的冗余/修改do-loops语法/等等重写Matlab代码,从而写了两次Fortran代码(用于蒙特卡罗模拟;不同的上下文)。
Julia
- hackernews上的Lofkin:
就个人而言,我尝试转到Julia,但速度缓慢的高阶函数,核心数据基础设施的高流失率,以及没有Pymc 3,这些都让我在pydata待了更长一点。我已经拴在numba上了。
- hackernews上的Buttons 840:
我专业使用Python 8年了,这是我最喜欢的语言。我有点常使用numpy和scikit-learn。这么说,最近,我真的很享受学习Julia的过程。它简单易学,并且确实表现良好(读:很快)。事实上,我认为学习Julia将会和学习一些诸如numba一样有用,并且提供相似的(有人说会略胜一筹)性能。
- hackernews上的idunning:
作为那种在日常工作(及编外项目)中几乎完全使用Julia的人中的一员,我认为作者对Julia的大部分想法都是正确的。我认为这个语言很棒,使用它让我的生活更美好。在我看来有一些包实际上比它们在其他语言中的等价物更好。另一方面,我对那些不完美的事物拥有更高的容忍度,我能自己理出头绪(幸运的是有时间这样做),并且如果不存在的话(在每一点上),我愿意为它编码。当然,对大多数的人来说,并不是这样的,但没关系。作者不愿意冒着Julia将会不“存在”的风险,这很公平。它肯定尚未完成,但它正在完成的路上。虽然,我有信心,它会存活下来(并且繁荣发展),并且继续增长不充实的社区。我有一种感觉,在一两年左右,最终,作者将找到他到Julia王国之路。
- reddit上的niksko:
我同意Julia主题。它潜力巨大,并且它基本上是专门为这些类型的应用准备的,但现在还没有社区和支持。我花了一个学期进行计算进化动力学领域的一个小的研究项目,而最繁琐最困难的部分是让Julia绘制我所想要的图。另外,那个时候,它还没有支持文档字符串 :/。它速度快,炫,但不够成熟。
- reddit上的KG7ULQ:
在我学习Coursera上的Ng ML课程后,我看了看,似乎要做的事情就是使用Python……但必须学习几个大库,包括你提到的那些。然后我看到了Julia,觉得我还不如学习它,因为它已经内置了所有的线性代数和SIMD相关的东西,并且性能更好。它的确看起来像是ML的“最佳”语言。
其他语言 (我忘记提的那些)
- hackernews上的leni536:
C++并没有做错什么。对于线性代数,我使用armadillo库,它是LAPACK和BLAS一个非常棒的封装 (并且也快!)。出于某些原因,科学家有点怕C++。由于某些原因,你“不得不”在一个“更容易的”语言中进行原型。当然,你你能把C++当成计算器而不是解释语言,但我看到人们卡在原型语言的计算上,最终并没有把它带到一个更快的平台上。要点是:C++对于科学计算并不难。
- reddit上的leni536:
对我来说,如果有什么会替换掉Python,那么Scala应该是最可能的候选者。我认为,函数式语言很好的适用于数学工作,并且它在JVM上,因此原型可以变成生产代码,而不需太多开销就可以“到处”运行。Spark是Scala的杀手级应用。现在,我可以从原型到在任意大的数据集之上运行,并且之间不会有太多的障碍。
- reddit上的rpcope1:
[Scala]在编译的时候可能是慢,但它比CPython更安全,并且快得多(除了使用非字节码的代码和调用C/Fortran库之外),并且还有一些我现在在Python中及其想念的概念,例如,Option[T],隐式修改器,不废柴的map/reduce/filter,不废柴的lambda,等等。
2 - 监控之我见
总结监控领域的认知
概述
监控是整个运维乃至整个产品生命周期中非常重要的一环,可以事前及时预警发现故障,事后提供详实的数据用于追查定位问题。
目前业界存在各种开源监控产品,如Zabbix,ELK体系,Prometheus等等,各有自身的适用场景,所以选择基于一款开源的的监控系统会是事半功倍的事情。
监控目标
站在公司各业务角度考虑,整理如下四点目标:

- 对系统不间断实时监控: 实际上是对系统不间断的实时监控(这就是监控)
- 实时反馈系统当前状态: 我们监控某个硬件、某个系统,某个进程服务,都是需要能实时看到当前系统的状态,是正常、异常、或者故障
- 保证服务可靠性安全性:我们监控的目的就是要保证系统、服务、业务正常运行
- 保证业务持续稳定运行:如果我们的监控做得很完善,即使出现故障,能第一时间接收到故障报警,在第一时间处理解决,从而保证业务持续性的稳定运行;
监控方法
既然我们了解到了监控的重要性、以及监控的目的,那么下面我们需要了解下监控有哪些方法。

- 了解监控对象:我们要监控的对象你是否了解呢?比如 CPU 到底是如何工作的?
- 性能基准指标:我们要监控这个东西的什么属性?比如 CPU 的使用率、负载、用户态、内核态、上下文切换。
- 报警阈值定义:怎么样才算是故障,要报警呢?比如 CPU 的负载到底多少算高,用户态、内核态分别跑多少算高?
- 故障处理流程:收到了故障报警,我们怎么处理呢?有什么更高效的处理流程吗?
监控核心
我们了解了监控的方法、监控对象、性能指标、报警阈值定义、以及故障处理流程几步骤,当然我们更需要知道监控的核心是什么?
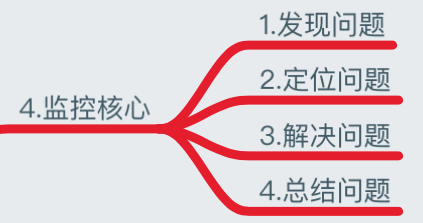
- 发现问题:当系统发生故障报警,我们会收到故障报警的信息 ;
- 定位问题:故障邮件一般都会写某某主机故障、具体故障的内容,我们需要对报警内容进行分析,比如一台服务器连不上:我们就需要考虑是网络问题、还是负载太高导致长时间无法连接,又或者某开发触发了防火墙禁止的相关策略等等,我们就需要去分析故障具体原因;
- 解决问题:当然我们了解到故障的原因后,就需要通过故障解决的优先级去解决该故障;
- 总结问题:当我们解决完重大故障后,需要对故障原因以及防范进行总结归纳,避免以后重复出现;
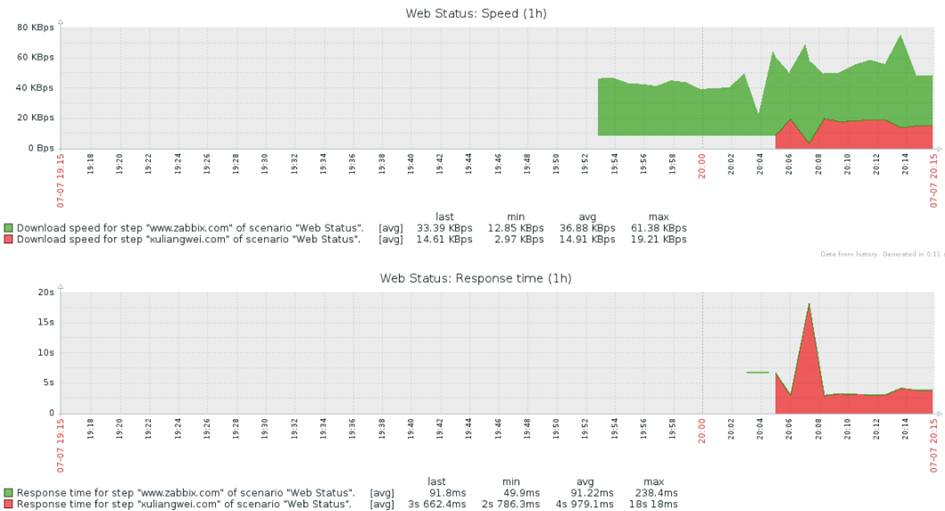
监控流程
基于 Zabbix 来构建整个监控体系生态圈
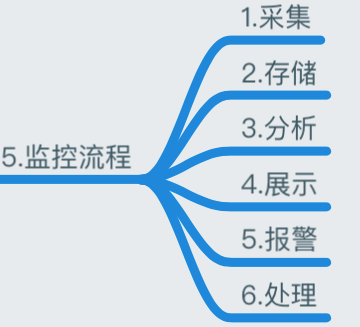
- 数据采集:Zabbix 通过 SNMP、Agent、ICMP、SSH、IPMI 等对系统进行数据采集;
- 数据存储:Zabbix 存储在 MySQL 上,也可以存储在其他数据库服务;
- 数据分析:当我们事后需要复盘分析故障时,Zabbix 能给我们提供图形以及时间等相关信息,方面我们确定故障所在;
- 数据展示:web 界面展示、(移动 APP、java_php 开发一个 web 界面也可以) ;
- 监控报警:电话报警、邮件报警、微信报警、短信报警、报警升级机制等(无论什么报警都可以);
- 报警处理:当接收到报警,我们需要根据故障的级别进行处理,比如:重要紧急、重要不紧急等。根据故障的级别,配合相关的人员进行快速处理;
监控指标
具体要监控些什么东西?那么我在这里进行了分类整理:
硬件监控
早期我们通过机房巡检的方式,查看硬件设备灯光闪烁情况判断是否故障,这样非常浪费人力,并且是重复性无技术含量的工作,大家懂得。

当然我们现在可以通过IPMI对硬件详细情况进行监控,并对 CPU、内存、磁盘、温度、风扇、电压等设置报警阈值(自行对监控报警内容编写合理的报警范围)
系统监控
基本全是 Linux 服务器,那么我们肯定要监控系统资源的使用情况,系统监控是监控体系的基础。
**监控主要对象: **

CPU 有几个重要的概念:上下文切换、运行队列和使用率。
这也是我们 CPU 监控的几个重点指标。
通常情况,每个处理器的运行队列不要高于3,CPU 利用率中“用户态/内核态”比例维持在70/30,空闲状态维持在50%,上下文切换
要根据系统繁忙程度来综合考量。
针对 CPU 常用的工具有:htop、top、vmstat、mpstat、dstat、glances
Zabbix 提供系统监控模板:Zabbix Agent Interface
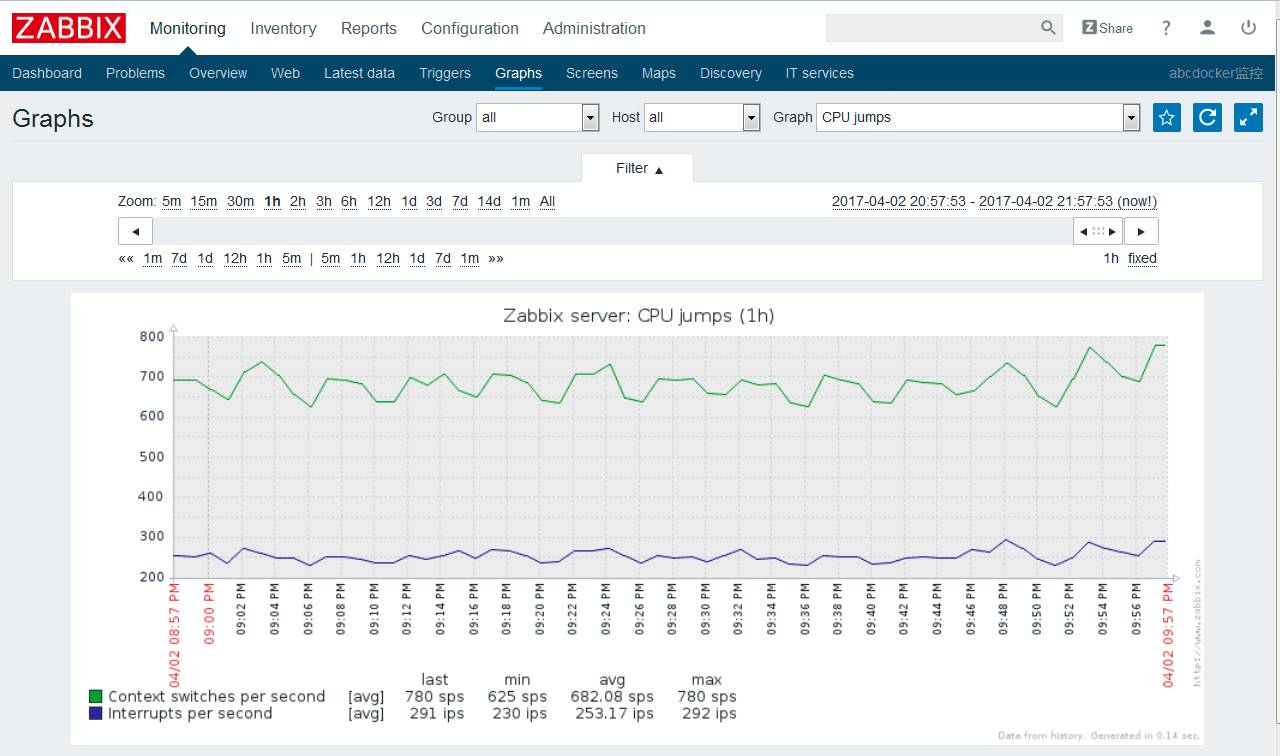
cpu整体状态
cpu上下文切换
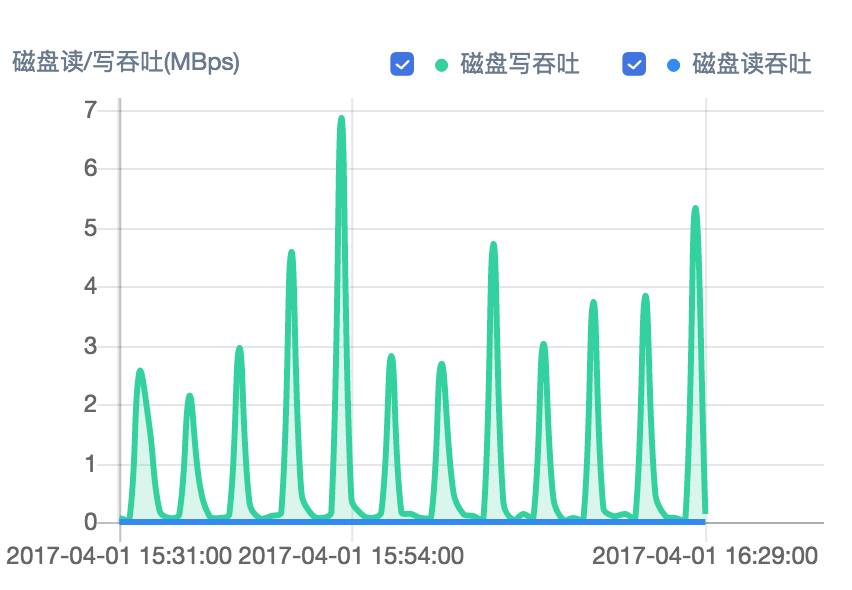
硬盘读写吞吐
其它的系统监控还有运行的进程端口、进程数、登陆用户、Open File 等(详细查看 zabbix 自带 OS Linux 模板)
应用监控
把硬件监控和系统监控研究明白后,我们进一步操作是需要登陆到服务器上查看服务器运行了哪些服务,都需要监控起来。 应用服务监控也是监控体系中比较重要的内容,例如:LVS、Haproxy、Docker、Nginx、PHP、Memcached、Redis、MySQL、Rabbitmq 等等,相关的服务都需要使用zabbix监控起来。
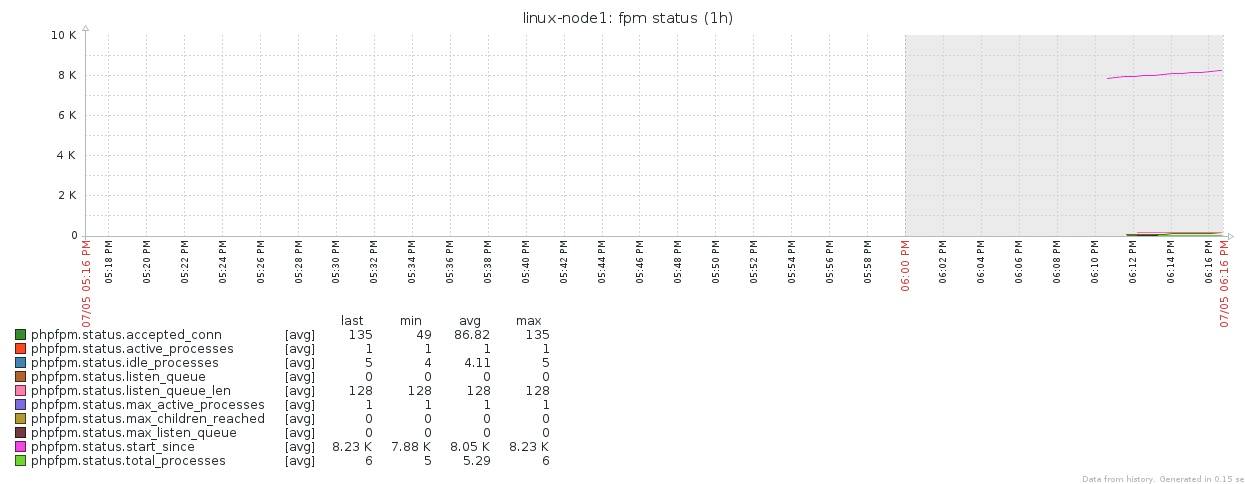
PHP-FPM状态
redis状态
Zabbix 提供应用服务监控:Zabbix Agent UserParameter Zabbix 提供的Java监控:Zabbix JMX Interface percona 提供 MySQL 数据库监控:percona-monitoring-plulgins
网络监控
网络监控是我们构建监控平台时必须要考虑的,尤其是针对有多个机房的场景,各个机房之间的网络状态,机房和全国各地的网络状态都是我们需要重点关注的对象。
需要借助于网络监控工具 Smokeping监控机房链路。
Smokeping 是 rrdtool 的作者 Tobi Oetiker 的作品,是用 Perl 写的,主要是监视网络性能,www 服务器性能,dns 查询性能等,使用 rrdtool 绘图,而且支持分布式,直接从多个 agent 进行数据的汇总。
CDN监控。。。对接第三方接口
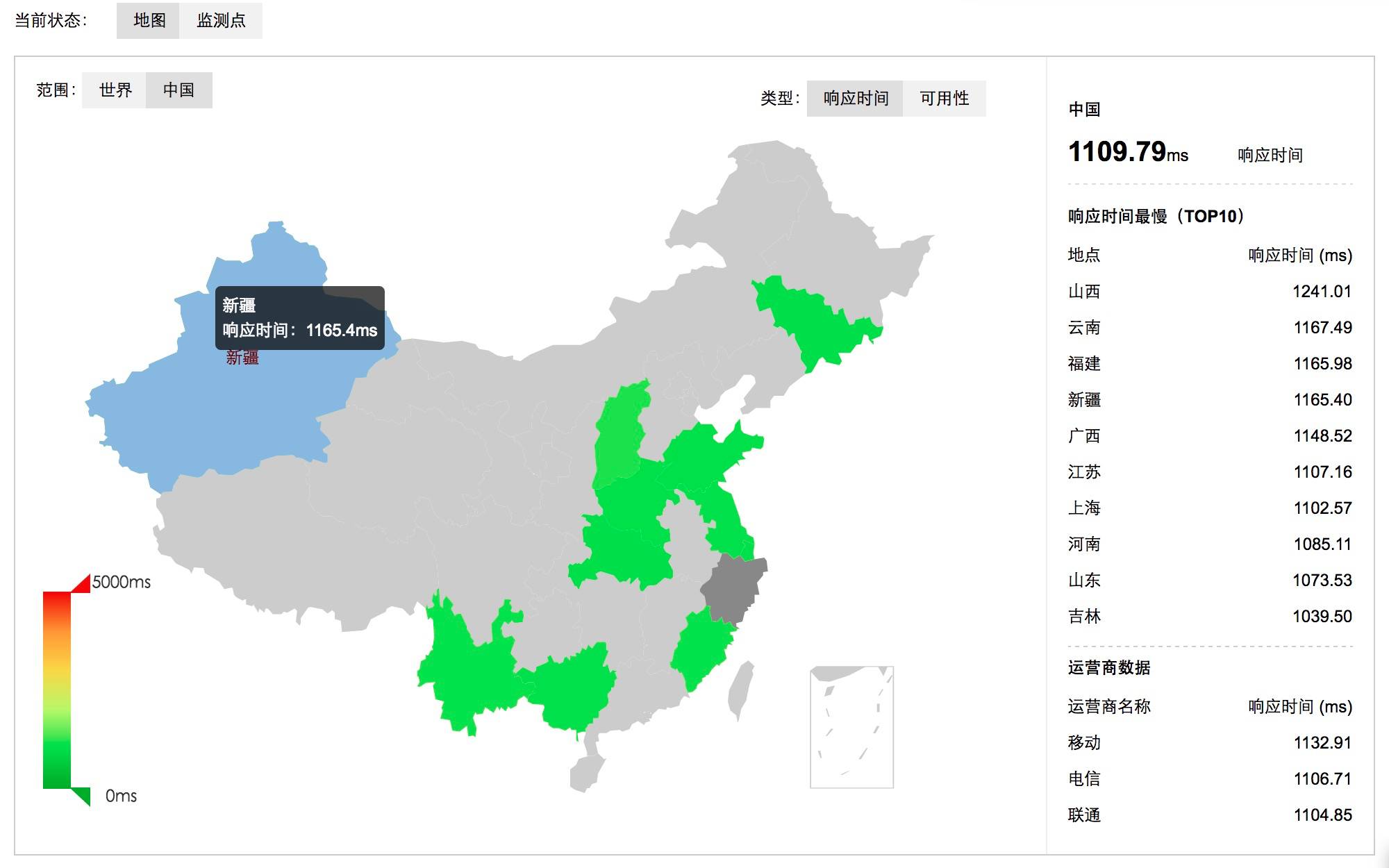
流量分析
网站流量分析对于运维人员来说,更是一门必须掌握的知识了。比如对于300.cn站点来说:
通过对网站来源的统计和分析,可以了解我们在某个网站上的广告投入有没有收到预期的效果。 可以区分不同地区的访问人数、甚至产品交易额等。 百度统计、google 分析、站长工具等等,只需要在页面嵌入一个js即可,但是,数据始终是在对方手中,个性化定制不方便,推荐使用google的piwik开源网站访问统计系统。
日志监控
通常情况下,随着系统的运行,操作系统会产生系统日志,应用程序会产生应用程序的访问日志、错误日志、运行日志、网络日志,我们可以使用 ELK 来进行日志监控。
对于日志监控来说,最见的需求就是收集、存储、查询、展示。
开源社区正好有相对应的开源项目: logstash(收集) + elasticsearch(存储+搜索) + kibana(展示) 我们将这三个组合起来的技术称之为 ELK Stack,所以说 ELK Stack 指的是 Elasticsearch、Logstash、Kibana 技术栈的结合。
如果收集了日志信息,那么如果部署更新有异常出现,可以立即在 kibana 上看到。
当然也可以通过Zabbix过滤错误日志来进行告警。
安全监控
虽然Linux开源的安全产品不少,比如四层 iptables,七层WEB防护 Nginx+lua 实现 WAF,最后将相关的日志都收至 ELK Stack,通过图形化进行不同的攻击类型展示。但是始终是一件比较耗费时间的事情,并且个人认为效果并不是很好。
API监控
由于微服务架构的推行, API 变得越来越重要,很显然我们也需要这样的数据来分辨我们提供的 API 是否能够正常运作。
监控 API 接口 GET、POST、PUT、DELETE、HEAD、OPTIONS 的请求, 可用性、正确性、响应时间为三大重性能指标

性能监控
全面监控网页性能,DNS 响应时间、HTTP 建立连接时间、页面性能指数、响应时间、可用率、元素大小等
Zabbix 提供 URL监控:Zabbix Web 监控
业务监控
没有业务指标监控的监控平台,不是一个完善的监控平台,通常在我们的监控系统中,必须将我们重要的业务指标进行监控,并设置阈值进行告警通知。
例如一个产品集群:
- 每天产生多少订单;
- 每天注册多少用户;
- 每天有多少活跃用户;
- 每天有多少推广活动;
- 推广活动引入多少用户;
- 推广活动引入多少流量;
- 推广活动引入多少利润;
等等 重要指标都可以加到 Zabbix 上,然后通过 screen 展示。
监控报警
故障报警通知的方式有很多种,当然我们最常用的还是短信,邮件
报警处理
一般报警后我们故障如何处理,首先,我们可以通过告警升级机制先自动处理,比如 Nginx 服务 down 了,可以设置告警升级自动启动 Nginx。
但是如果一般业务出现了严重故障,我们通常根据故障的级别,故障的业务,来指派不同的运维人员进行处理。 当然不同业务形态、不同架构、不同服务可能采用的方式都不同,这个没有一个固定的模式套用。
总结
- 监控是一个长期持续的项目, 需要特定的1-2人跟踪改进;
- 监控使用方是业务和运维;
- 业务方应提供监控项获取方法;
- 如果有投诉,先找监控项目组,没有做到“事先”发现问题,监控项目组应该承担其责任;
- 对外提供api,供业务方使用
3 - Github开源项目的正确贡献姿势
介绍个人的github项目贡献经验
常见的开源项目贡献指导里都是差不多的样子:
* 要先fork
* 然后change something
* 再然后fetch,rebase
* push origin, 最后发起pull request
具体到不同的项目,可能会要求更多的细节步骤,但大体如上。
这些都没错,但实际操作起来,和习惯不符。因为我一般是先clone一个项目,然后使用中发现有问题,会尝试去修改,fix OK的话,才会想着去贡献代码 可事情到了这一步,再按照一开始的方式操作,会平白无辜耗费很多时间,还涉及到已经修改完代码如何同步过去的问题。 以下是我个人总结的一套方法,屡试不爽乎。
这里我以k8s项目的贡献经历来举例,以备不时之需。git这个东西,不常用,会忘记的,即使你已经理解原理了。。。
首先clone K8s的项目代码。
git clone https://github.com/kubernetes/kubernetes.git然后自行编译 make, 使用中发现一些问题
就会去github的issue里找找看。。。竟然没人提这个问题,问问同事或同行,人家表示没碰到过你的问题, 好吧,自己尝试去修改... 不断编译 ... 测试... 最终OK了,我要贡献代码!!! 完啦,没有按照最佳习惯来,改动前忘记新建分支了。。。(这个习惯很重要,可以省掉很多麻烦) 只能如此操作了,可以来个大挪移到新建分支上
git stash git checkout -b fix_something git stash apply此时去github上fork下原项目,拿到fork后的项目地址,再来个偷天换日。
git remote rename origin upstream git remote add origin git@github.com:xiaoping378/kubernetes.git再然后就可以按一开始介绍的,fetch, rebase, push origin, 发起PR了。
git fetch upstream git rebase upstream/master # 有冲突就git mergetool git push origin fix_something # 然后去github页面发起pull request即可。注意事项 值的注意的是,以后在master分支上git pull,就是从upstream/master那里拉取的,和一般情况不一样的地方。 这样会少了烦人的merge msg(-ff可以解决), 还可以用简单的pull来同步上游代码。 更可以意淫自己是原项目的核心开发人员了。。。 以后本地同步fork的项目到上游的最新状态,这样操作:
git checkout master git pull git push origin master其实github上那个fork的项目,只是用来提PR的,这样可以在原项目的分支上任意玩耍了。当然你也可以用来备份一些比较大的feature
最后记录下个人的git global配置
# cat ~/.gitconfig [user] email = xiaoping378@163.com name = xiaoping378 [merge] tool = meld [push] default = simple [core] quotepath = false
4 - Golang开发-glog日志库
介绍Golang开发中的glog日志库
基于Golang 1.7.5版本
软件项目里的日志输出是很重要的环节,可以用于日后BI分析,或者线上调试(万能调试大法printf)等等。
对于当年刚入软件行业时,自己的printf("11111\n")的做法,记忆犹新呀,调试完再删掉自己胡乱加的打印语句,偶尔还有漏删的情况,就commit,push上去了。
golang语言里有个golang/glog包,是类似google内部glog的开源实现,其可以做到无侵入式调试程序,主要是通过启动时命令行传参来控制打印级别。
有以下特性,
- 有四个级别的打印 Info, Warning, Error, Fatal,级别越来越高,分别都支持格式化输出Infof, Warningf, Errorf, Fatalf
- 支持 -v传参,指定打印级别
- 支持 -vmodule=file=2, 指定特殊文件开启打印,避免日志输出过多。
- 支持 -log_dir="", 指定日志输出目录, 默认会按级别输出/tmp目录下, 高级别的会记录到低级别里日志文件里
下面举个简单的例子
//file name: glog.go
package main
import (
"flag"
"github.com/golang/glog"
)
func main() {
flag.Parse()
//flag.Set("logtostderr", "true")
defer glog.Flush()
glog.Info("这里是Info级别的日志")
glog.Warning("这里是Warning级别的日志")
glog.Errorf("这里是Error级别的日志: %s", "error")
glog.V(3).Infoln("级别3的日志")
}
代码如上运行,你需要执行go get github.com/golang/glog下载依赖包, 然后运行
➜ go run glog.go -v 3
E0408 09:35:38.703186 8663 glog.go:15] This is a Error log error
Error级别的会输出到标准输出,并记录到文件,
日志默认输出到/tmp目录, 每次执行都会记录新的文件,日志文件如下样式命名, glog是文件名,air13是主机名,xxp是用户名
➜ ls /tmp/glog.* -l -rw-rw-r-- 1 xxp xxp 260 4月 8 10:11 /tmp/glog.air13.xxp.log.ERROR.20170408-101153.12771 -rw-rw-r-- 1 xxp xxp 405 4月 8 10:11 /tmp/glog.air13.xxp.log.INFO.20170408-101153.12771 -rw-rw-r-- 1 xxp xxp 334 4月 8 10:11 /tmp/glog.air13.xxp.log.WARNING.20170408-101153.12771 lrwxrwxrwx 1 xxp xxp 46 4月 8 10:11 /tmp/glog.ERROR -> glog.air13.xxp.log.ERROR.20170408-101153.12771 lrwxrwxrwx 1 xxp xxp 45 4月 8 10:11 /tmp/glog.INFO -> glog.air13.xxp.log.INFO.20170408-101153.12771 lrwxrwxrwx 1 xxp xxp 48 4月 8 10:11 /tmp/glog.WARNING -> glog.air13.xxp.log.WARNING.20170408-101153.12771-v 3指定运行时的记录的日志级别,因为3>=3, 这样V(3).Infoln会输出, 如果是传入-v 2, 则不会go run glog.go -v 2 -logtostderr=true, 则会关闭记录文件,输出到标准输出。 当然可以在程序里加上flag.Set("logtostderr", "true")来关闭记录文件。
总之,glog包对日志的控制非常实用和灵活,大型Golang项目必备包之一。
5 - VSCode-开发已有的java项目
介绍如何在vscode中开发编译调试已有的java的项目
个人经验记录:
install deps
clean workspace
代开设置 Ctrl+Shift+P, 输入
clean java workspaceand restartsupport lombok
java代码出了名的冗长,lombok可以优雅解决此类问题,如果项目依赖了lombok, vsocde打开java项目就会显示各种
cannot be resloved错误,下面是我个人的配置,其中
java.jdt.ls.vmargs的配置(看个人项目maven依赖和安装路径了),会消除错误,并可以支持跳转:{ "window.menuBarVisibility": "toggle", "window.zoomLevel": 1, "explorer.confirmDelete": false, "workbench.colorTheme": "Solarized Dark", "files.associations": { "default": "toml" }, "editor.fontLigatures": true, "java.configuration.checkProjectSettingsExclusions": false, "go.autocompleteUnimportedPackages": true, "java.jdt.ls.vmargs":"-javaagent:/home/xxp/.m2/repository/./org/projectlombok/lombok/1.16.20/lombok-1.16.20.jar -Xbootclasspath/a:/home/xxp/.m2/repository/./org/projectlombok/lombok/1.16.20/lombok-1.16.20.jar" }
参考链接
6 - MongoDB之初见
介绍MongoDB的基本使用。
- 手动启动
# 下载二进制
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.4.9.tgz
tar -zxvf mongodb-linux-x86_64-3.4.9.tgz
ln -s $PWD/mongodb-linux-x86_64-3.4.9/bin/* /home/xxp/Software/bin
# 创建数据存储目录
mkdir mongodb
sudo chown -R $USER ./mongodb
mongod -dbpath=$PWD/mongodb
默认监听27017, 根据情况选择关闭warning。
- 推荐调试方法
默认可以使用mongo进入shell交互模式,
亦可使用图形管理界面,推荐robo3T, 目前1.1.1版本在ubuntu桌面上有crash问题,需要如下操作:
curl -O https://download.robomongo.org/1.1.1/linux/robo3t-1.1.1-linux-x86_64-c93c6b0.tar.gz
tar zxvf robo3t-1.1.1-linux-x86_64-c93c6b0.tar.gz
mkdir ~/robo-backup
mv robo3t-1.1.1-linux-x86_64-c93c6b0/lib/libstdc++* ~/robo-backup/
robo3t-1.1.1-linux-x86_64-c93c6b0/bin/robo3t
- 基本使用
shell里敲mongo进入交互界面,
手续推荐查看mongodb中文文档
7 - Openldap之拨云见日
介绍Openldap的原理。
很早就听说LDAP/AD之流的企业级概念,认为是做统一用户认证的,具体怎么使用对接,一直有点儿糊涂,今天决定搞明白这些,并深入实践下openldap。
未完...TODO
8 - Casbin的权限管理解读
介绍Casbin的权限模型管理的用法。
项目一般都要包含权限管理功能,或集成IAM,或自身实现。本文介绍一个强大、高效的开源访问控制框架--Casbin。
基本介绍
Casbin的由来,是出自开源作者罗杨的一篇论文《PML:一种基于Interpreter的Web服务访问控制策略语言》,该论文的主要摘要如下:
为了保护云资源的安全,防止数据泄露和非授权访问,必须对云平台的资源访问实施访问控制.然而,目前主流云平台通常采用自己的安全策略语言和访问控制机制,从而造成两个问题:
- (1)云用户若要使用多个云平台,则需要学习不同的策略语言,分别编写安全策略;
- (2)云服务提供商需要自行设计符合自己平台的安全策略语言及访问控制机制,开发成本较高.
对此,提出一种基于元模型的访问控制策略描述语言PML及其实施机制PML-EM. PML支持表达BLP、RBAC、ABAC等访问控制模型. PML-EM实现了3个性质:
- 策略语言无关性
- 访问控制模型无关性
- 程序设计语言无关性
从而降低了用户编写策略的成本与云服务提供商开发访问控制机制的成本. 在OpenStack云平台上实现了PML-EM机制.实验结果表明,PML策略支持从其他策略进行自动转换, 在表达云中多租户场景时具有优势.性能方面,与OpenStack原有策略相比,PML策略的评估开销为4.8%.PML-EM机制的侵入性较小,与云平台原有代码相比增加约0.42%.
目前Casbin的权限策略管理支持主流的ACL、RBAC、ABAC、RESTful等模型,实现的编程语言主要有Go、java、Nodejs、PHP、Python、.Net、C++、Rust等。目前Go和Java的实现最为全面。
先介绍下主流的访问控制模型:
- ACL(access control list):是一种与访问对象关联的权限列表,在基础设施领域应用非常广泛:
- 文件系统:用户(组)对文件或进程等的访问权限控制
- 网络:常见的有防火墙(安全组、路由器、交换机)内的对目的IP和端口的规则控制
- SQL:库、表的权限管理
- LDAP:层级结构的实体权限管理:网络域权限管理...
- RBAC(role-based access control):基于角色的权限控制,围绕角色和权限定义的策略中立的访问控制机制,和组ACL等价,具体表现为在用户和权限之间加了一层角色,先建立具有某种权限的角色,然后用角色和用户绑定,目前多用于管控类业务系统的权限管理,还支持支持角色权限继承。
- ABAC(Attribute-based access control):基于属性的权限控制,属性可以是用户侧(所属组织、访问IP、访问时间)或资源侧(帖子的评论开关、留言再编辑)的,因为用户或资源的属性是动态的,不像前面两个(需要预先定义好策略,略显死板,,,)被称为是“下一代”的权限模型,可以实现更多元化的策略策略,比如
- 限制用户在什么固定时间段才可以编辑自己的帖子
- 用户只能修改自己项目下的某些资源等
和Casbin结合,使用的基本示意图如下:
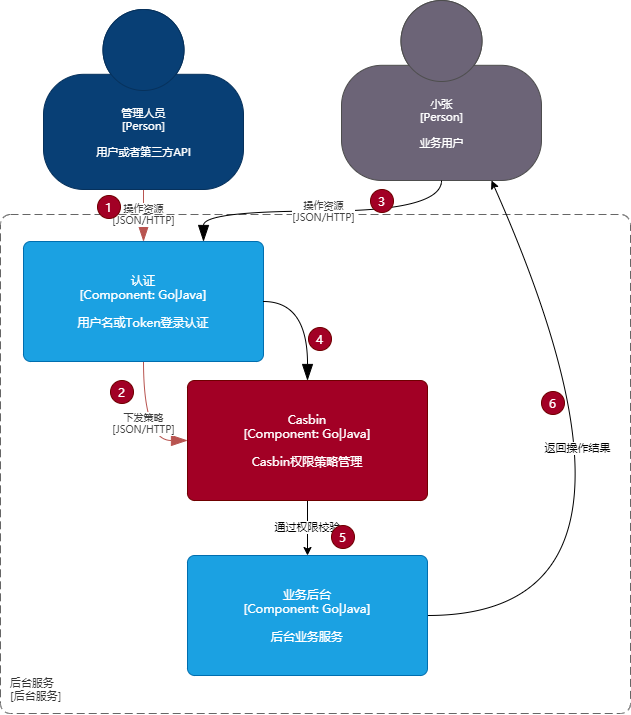
- 1-2为管理人员下发权限策略
- 3-6为用户日常操作资源的简易流程,实际应用场景一般如下:
@startuml
!theme aws-orange
用户 -> 认证中心: 登录操作
认证中心 -> 缓存: 存放(key=token+ip,value=token)token
用户 <- 认证中心 : 认证成功返回token
用户 -> 认证中心: 下次访问头部携带token认证
认证中心 <- 缓存: key=token+ip获取token
Casbin <- 认证中心: 存在且校验成功,则进入授权校验
Casbin -> 其他服务: 权限合规,则跳转到用户请求的其他服务
其他服务 -> 用户: 信息
@enduml
抽象模型
正如上面提到的,要支持这么多的权限模型,,所以Casbin基于开头提到的PML(PERM modeling language)引入一种抽象的元模型控制,其中PERM是指的Policy, Effect, Request, Matchers,具体工作流如下:
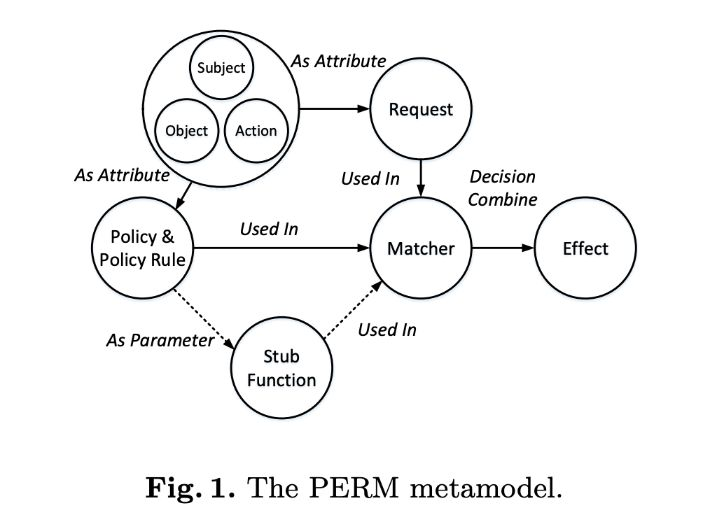
这里的PERM是Casbin在启动时要加载的抽象校验模型,可以理解成一种权限校验模板。 简单说个场景串下这里的概念:
- 管理员分配给用户权限Policy,可以得到
谁能操作什么资源的信息 - 用户发起请求Request,可以得到
谁要操作什么资源的信息 - Casbin拿到Request和Policy做匹配Matcher,也支持自定义函数匹配。
- 根据匹配结果Effect来决定是否允许用户的操作
实际场景中,用户可能被分配了多个权限(角色),那具体权限校验如下:
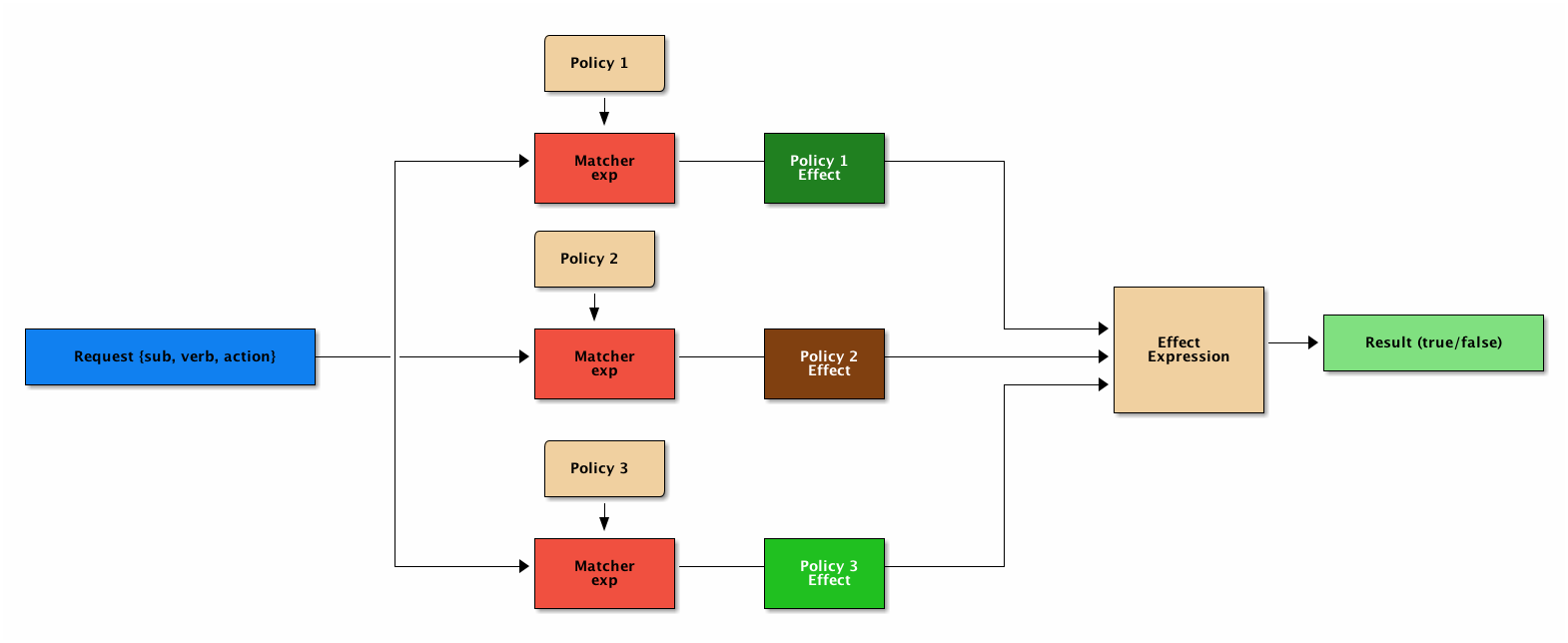
既然是一种语言,就是有语法的,PERM语法至少要有四部分:[request_definition], [policy_definition], [policy_effect], [matchers]。
具体就不展开介绍了,可自行官网详读,effect部分具备SQL背景可能好理些,,,理解不了也没关系,目前就内置了5种:
| Effect | 含义 | 样例 |
|---|---|---|
| some(where (p.eft == allow)) | allow-override | ACL, RBAC, etc. |
| !some(where (p.eft == deny)) | deny-override | Deny-override |
| some(where (p.eft == allow)) && !some(where (p.eft == deny)) | allow-and-deny | Allow-and-deny |
| priority(p.eft) || deny | priority | Priority |
| subjectPriority(p.eft) | priority base on role | Subject-Priority |
奉劝各位看官,既然是语法,就不要纠结里面的命名和写法,较真...就是这么定义的,知道能都有哪些写法就可以了...,实际使用中往往改动Macter的部分。
按场景举例
ACL模型
先定义Casbin要加载的PERM Model,我使用在线编辑器定义一个ACL典型模型:
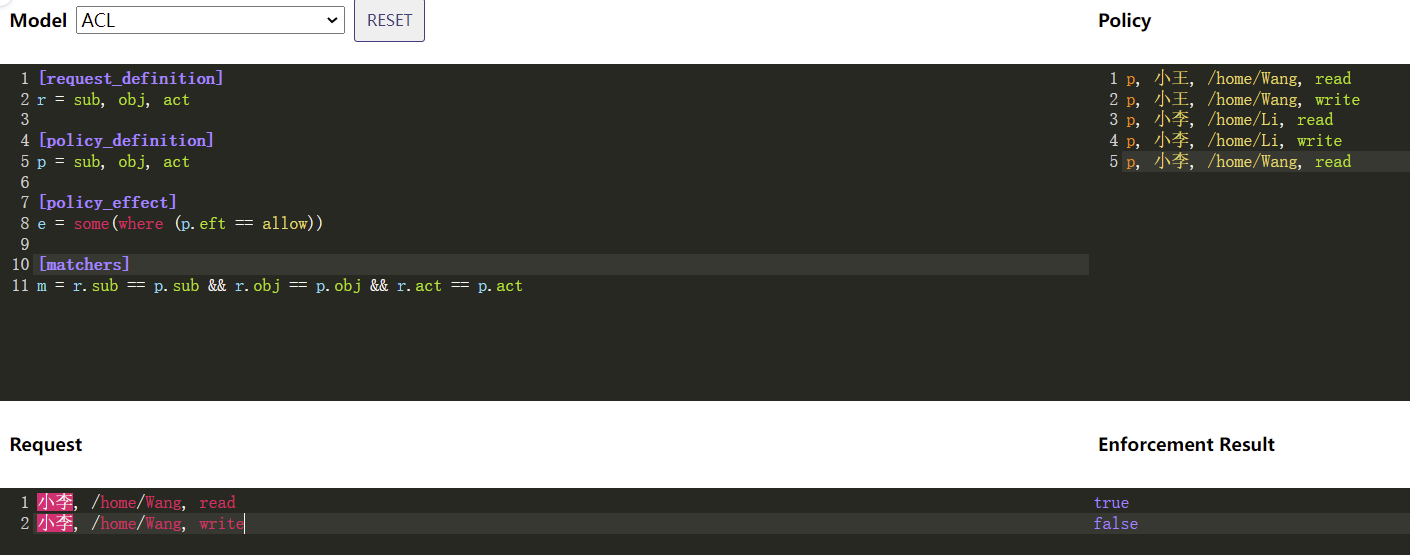
解读如下:
- 左上侧为Casbin启动时要加载的标准ACL Model配置,不需要改动
- 右上侧为Policy部分,属于管理员要分配权限时要改动的部分:示例中定义了5条规则,小王和小李对自己的Home目录可以读写,而小李额外可以读取小王的Home目录
- 左下角Request表明用户的请求,一般是从用户实际发起的请求中获取信息,组合好格式后,用API发起校验,示例中小李发起读和写小王的操作
- 右下角为权限校验结果:示例中小李的写操作被拒绝了
RBAC模型
下图模式的在线编辑地址
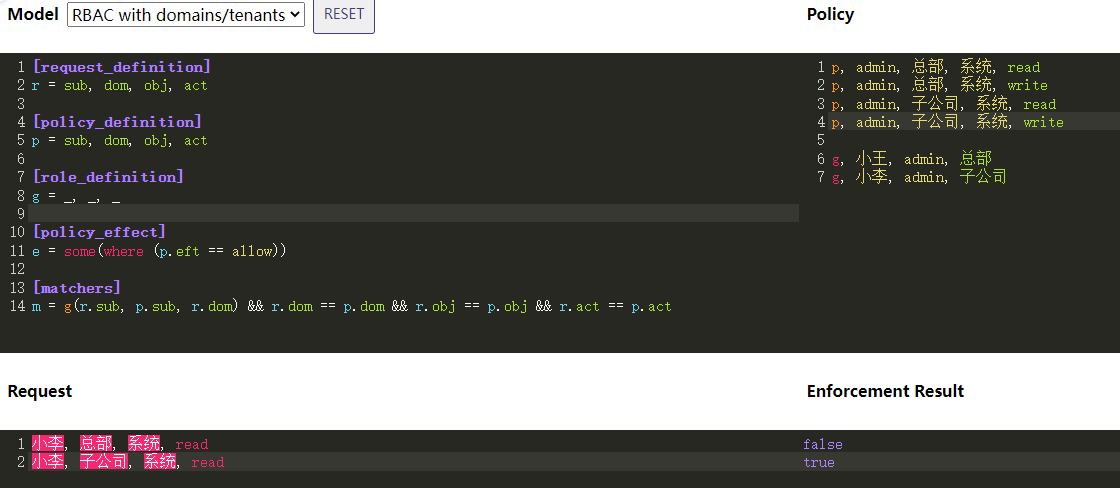
Macters里的g(r.sub, p.sub, r.dom) 将检查用户 r.sub 在域内 r.dom 是否具有角色 p.sub ,这是该匹配器的工作方式。
ABAC模型
上图中RBAC中的Matcher如下修改,即实现了ABAC的模型校验。表明用户必须是被访问资源的Owner才可以操作符合角色权限内的资源。
m = r.obj.Owner == r.sub && (g(r.sub, p.sub, r.dom) && r.dom == p.dom && r.obj == p.obj && r.act == p.act)
总结
Casbin提供了非常灵活的权限校验模型,还提供了丰富的API,方便更便捷的实现业务场景功能, 后面会针对具体的项目开展更贴地气的解读。
参考
9 - Windows Terminal终端入坑指南
介绍windows terminal安装和oh-my-zsh的配置
为了这个东西,重新安装了系统,目前是在windows LTSC 2021版本下的使用指南。 在IT界Terminal和Console差不多是一个意思,同属于界面层面的,不少人老和Shell搞混了,特此说明下Shell一般是指的Bash、zsh、PowerShell、cmd等。
安装
为了使用Windows Terminal,在春节期间,重新安装了LTSC 2021版本的系统(之前一直用的LTSC 2019)。
它对操作系统内部版本的最低要求为
18362.0,通过Win+R输入winver可以确认本机系统是否支持。
目前有三种办法安装(本人选用的第二种):
是在应用商店中搜索
Windows Terminal,安装即可。通过Github release页面下载安装包,
Add-AppxPackage Microsoft.WindowsTerminal_<versionNumber>.msixbundle
- 通过命令行winget、Chocolatey 、Scoop 安装,下面以winget为例:
winget install --id=Microsoft.WindowsTerminal -e
配置
现在基本可以图形界面配置了,按照自己的习惯图形操作即可,网上一坨坨的教程,此处不表。
默认配置保存在了%LOCALAPPDATA%\Packages\Microsoft.WindowsTerminal_8wekyb3d8bbwe\LocalState\settings.json
技巧
- 快捷键
- 新建终端 --
Ctrl+Shift+t - 切换终端 --
Alt + Num, (我这里修改过了)
- 新建终端 --
- Quake窗口
- 快捷键是Win + ` , 可以快速从屏幕上半区换出终端窗口
GitBash
本人环境VSCode和git-bash都是绿色版本了,免去了每次重装系统,都进行各种重复的配置操作.
没有环境的可以自行通过上面的连接下载GitBash,后面有时间会尝试下
WSL和WSL2。
中文乱码
需要添加环境变量到~/.bashrc或者~/.zshrc中。
export LANG=zh_CN.UTF-8
绿色改造
绿色改造的核心,一个是安装时不默认安装在C盘,另一个就是设置HOME的系统环境变量,Git-Bash每次启动是可以根据HOME变量,决定加载配置的路径的。
设置系统环境变量,两种办法:
图形界面操作:
Win+x-> 系统 -> 高级系统设置 -> 环境变量, 自行添加HOME变量。在PowerShell命令行中设置环境变量,执行完即可生效。
[Environment]::SetEnvironmentVariable("HOME", "D:\xxp", "User")
我这里是D:\xxp目录,这样的话,那些ssh、git、vscode、bash、zsh的自定义配置,都可以免去重装再来一次的痛苦了。
还可以把日常用到exe小工具,也放到$HOME/bin目录下,再加到PATH环境变量里。
[Environment]::SetEnvironmentVariable("Path", [Environment]::GetEnvironmentVariable("Path", "User") + ";D:\xxp\bin","User")
oh-my-zsh主题改造
现在有人直接把zsh装上,然后再安装github上的oh-my-zsh主题,但是启动速度会慢一些,本来bash就比cmd启动慢了,,,
我是在bash的基础上改造下主题,修改Git\etc\profile.d\git-prompt.sh文件,详见这里
之前一直是Bash的基础上,修改了下主题凑活用着。其实可以直接使用zsh的,记录下大致操作。
之前在网上看过的的教程大多是在
bashrc里再启动zsh,会慢上加慢的,我就一直没弄,后来觉得是可以做个Git-zsh环境的。
- 下载zsh二进制
现在msys2上的安装包,都变成zst格式(Facebook家出的)的压缩包了,还需要下载解压工具,我平常使用的就是7z,这里找了个7z with ZS的工具。
解压到GitBash安装的根目录上。主要是/etc/zsh和/usr目录。
- 安装oh-my-zsh主题
sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
- terminal和vscode中使用zsh.exe
- 直接指定
zsh.exe的路径 - 还需要在
~/.zshrc的PATH里添加/mingw64/bin,不然会提示找不到git,
如下是Terminal的配置:
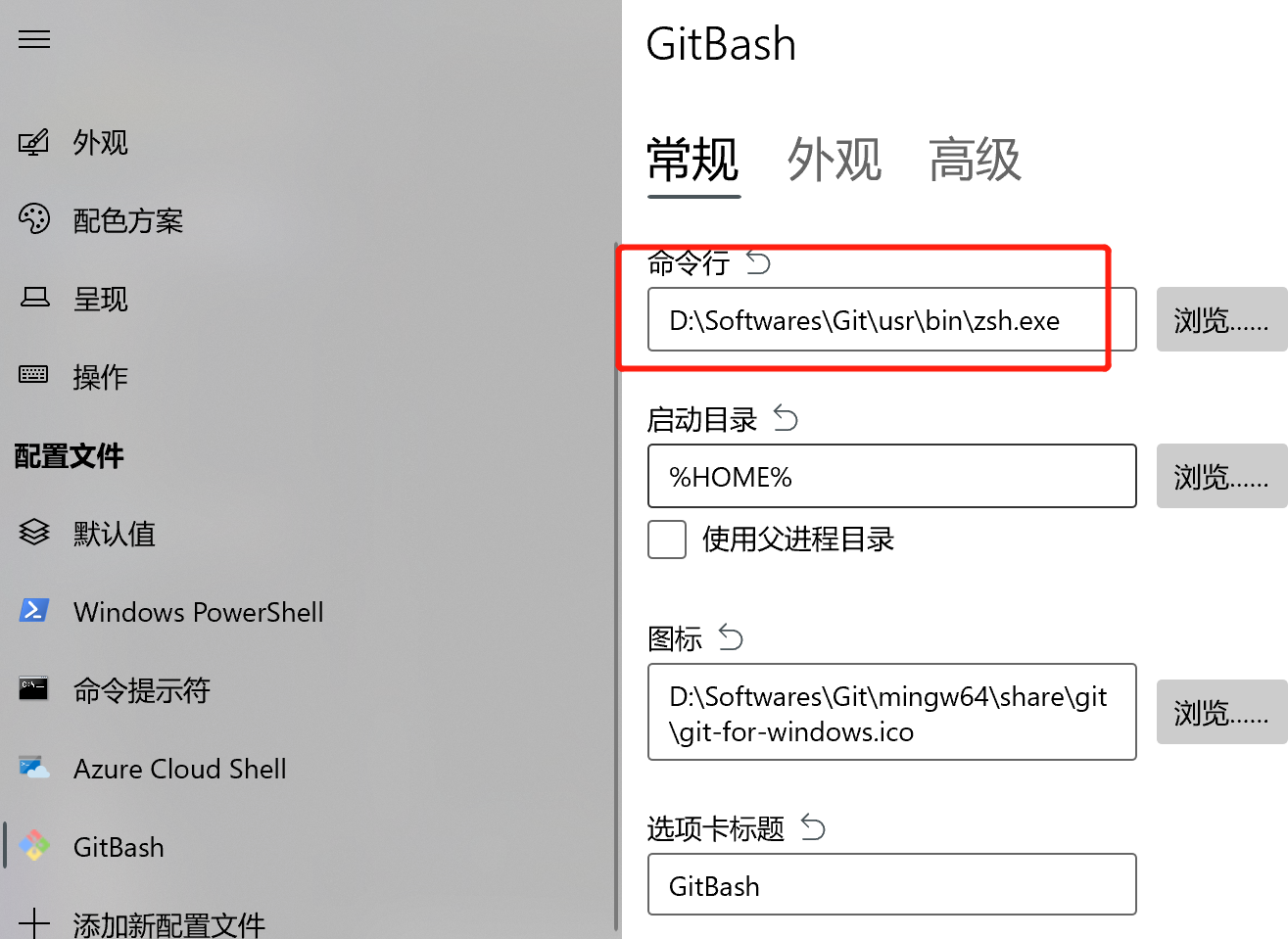
如下是vscode中的配置:
"terminal.integrated.profiles.windows": {
"git-bash": {
"path": "D:\\Softwares\\Git\\usr\\bin\\zsh.exe",
"args": []
}
},
"terminal.integrated.defaultProfile.windows": "git-bash",
10 - Golang单仓monorepo协作的设计与实践
介绍Golang单仓monorepo协作的设计与实践
什么是monorepo
多代码仓合一就是nomorepo,目前在前端领域比较火热,国外大厂如Google、Facebook、Microsoft内也在公司级采用此模式,国内的浮躁,是个项目就上微服务架构的现状,导致代码仓动辄就上几十个,感觉也适合此模式。这东西说起来简单,实际运转起来,需要相应的支撑工具,如代码仓管理、CI/CD适配等,本文主要设计一套可行的方案及记录实践关键过程。
这里说下背景:为什么要研究这个,最近接手一个项目,发现团队积累几乎没有、需求响应进度慢、新成员接手难度大,另外该项目竟然有上百个仓库,哪些和线上正在运行的服务对应,也没有说明,,,相应的协作管理手段也薄弱,总之就是乱,。个人是信服
康威定律(组织沟通方式会通过系统设计表达出来,反之亦成立)的,所以打算尝试下单仓的协作模式,一来可以梳理下以前的需求实现,二来促进组员交流沟通,制定些开发规范和统一框架之类的也好落地。
代码目录结构
CODEOWNERS机制
CI/CD机制
工具实践Lighthouse
11 - TiDB分布式数据库
TiDB分布式数据库的介绍和深度探索
主要介绍TiDB周边生态和实践体验
11.1 - TiDB初体验
TiDB 初体验安装介绍
安装
安装环境要求:
- Mac或者单机Linux环境
- 可以连接外网
- 执行命令安装
TiUP工具,官方运维管理工具。
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
命令会有关键信息输出:添加了证书、修改了PATH变量等,需要声明下环境变量,以使tiup命令能被找到。
- 声明系统环境变量
# 因个人环境,此处会有差异
source ~/.zshrc
可以echo $PATH下,看到/root/.tiup/bin被加到了最前面。
- 启动单实例集群
直接执行tiup playground命令默认会运行最新版本的TiDB集群,其中TiDB Server、TiKV、PD 和 TiFlash 实例各 1 个:
tiup playground
具体如下图所示,需要另开一个终端,使用mysql发起连接:
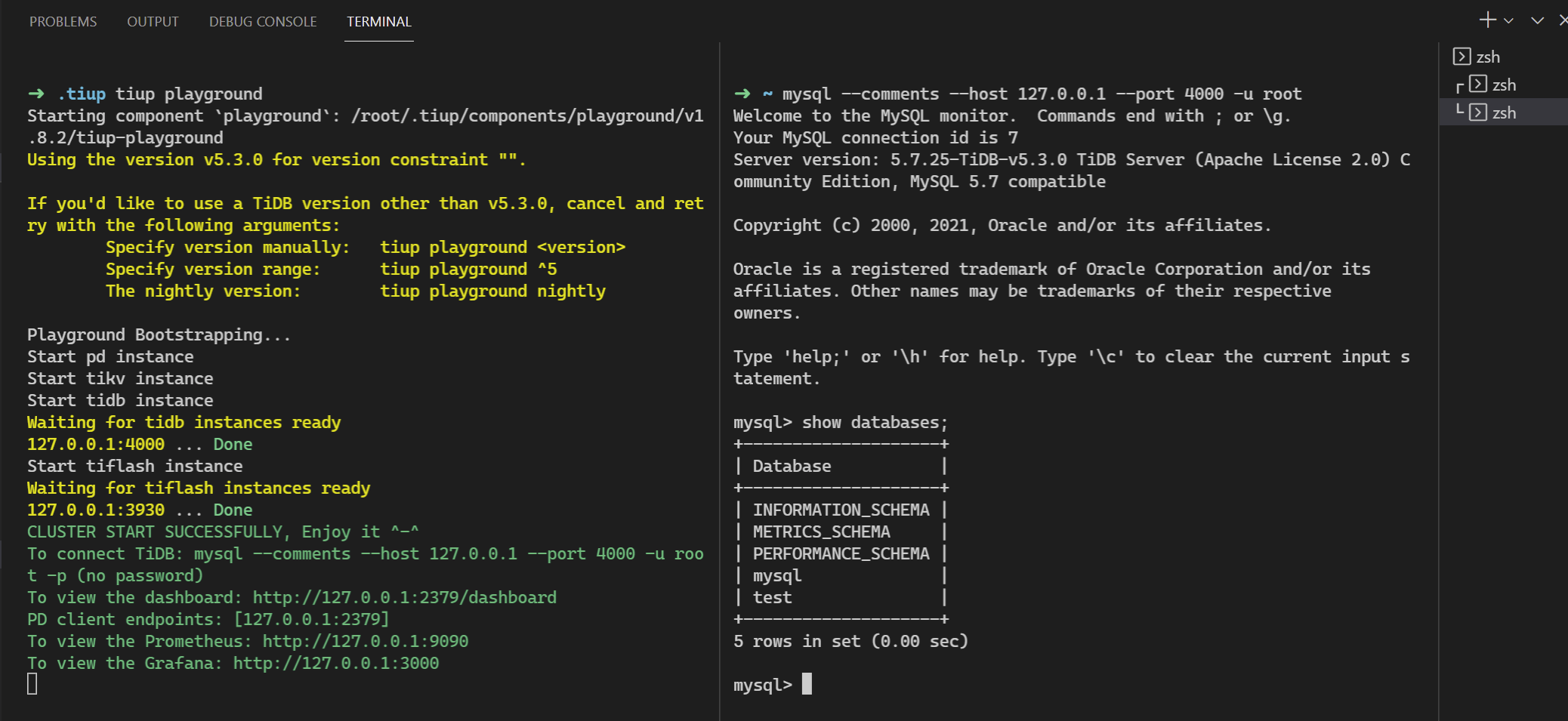
目前tidb playground默认启动监听在127的地址,可以通过--host参数更改,但还不能更改端口(经查代码是写死了端口)。
- 其他可修改参数,可通过
tiup playground -h查看。 - dashboard的默认root用户没有密码,如果是公网暴露了,建议如下添加密码(我这里设置了root密码为
tidb):
mysql -h127.0.0.1 -P4000 -uroot
alter user 'root' identified by 'tidb';
- grafana的登录密码,默认为admin/admin
tiup update --self可升级tiup命令
mysql客户端可通过
yum install -y mysql或者apt install mysql-client安装。
集群
没有多节点的环境,折腾了一下,要单机玩这个模式的话,需要hack的东西太多,,,目前还不建议这么搞,等有时间看能不能提个PR.
TIDB Server
处理client的SQL请求.
PD
提供全局时钟和Region调度和管理(扩缩容)。
TIKV
使用rocksDB实现数据持久化,基于此实现了分布式存储引擎,其中的核心点可以理解为以下三点:
- 事务
- MVCC
- Raft
分布式事务Percolator
基于时间戳的两阶段提交事务解决方案。
MVCC多版本并发控制
COW的本质。默认revision大的为最新值,
多副本Raft一致性
Leader选举:
Term状态变化,follower -> (random timeout) -> candidate -> leader. 此过程因为网络延迟问题,很可能是进行多轮选举。
@startuml
!theme aws-orange
TiKV1 -> TiKV1: 随机选举时间到,切换为candidate角色,进入term2,发出选举信息
TiKV1 -> TiKV2: 发起选举,term=2
TiKV1 -> TiKV3: 发起选举,term=2
TiKV2 -> TiKV2: 对比term(非拜占庭环境,大家默认信任term大的)
TiKV3 -> TiKV3: 对比term
TiKV2 -> TiKV1: 投一票
TiKV3 -> TiKV1: 投一票
TiKV1 -> TiKV1: 超过一半投票(2x+1),成为Leader
TiKV1 -> TiKV2: 心跳保活
TiKV1 -> TiKV3: 心跳保活
TiKV1 -> TiKV1: 异常了
TiKV2 -> TiKV2: 心跳超时,切换candidate角色,进入term3
TiKV2 -> TiKV3: 发起选举
TiKV3 -> TiKV2: 对比term,并投一票
TiKV2 -> TiKV2: 加上自己的一票,超过一半投票,成为Leader
@enduml
leader负责读写请求,follower负责数据多副本复制。日常心跳保活,出问题后,重新选举。
数据写入:
- propose -> append (local) -> Replicate (remote append) -> commited -> apply
@startuml
!theme aws-orange
用户 -> TiDB_Server: 发起事务数据写入
TiDB_Server -> TiDB_Server: 解析语句,SQL -> KV
TiDB_Server -> PD: 获取KV元信息
PD -> TiDB_Server: 告知该key的range leader信息(TiKV1)
TiDB_Server -> TiKV1: 发起propose
TiKV1 -> TiKV1: 本地append为raft_log
TiKV1 -> TiKV2: 发起Replicate复制
TiKV1 -> TiKV3: 发起Replicate复制
TiKV2 -> TiKV2: 本地append为raft_log
TiKV3 -> TiKV3: 本地append为raft_log
TiKV2 -> TiKV1: 反馈已记录成功
TiKV3 -> TiKV1: 反馈已记录成功
TiKV1 -> TiKV1: 收到大多数节点反馈,进入commited状态
TiKV1 -> TiKV2: 发起commited确认
TiKV1 -> TiKV3: 发起commited确认
TiKV2 -> TiKV1: 进入commited
TiKV3 -> TiKV1: 进入commited
TiKV1 -> TiKV1: 收到大多数节点反馈,进入apply状态,此时业务数据才算真正落盘
TiKV1 -> TiKV2: 发起apply确认
TiKV1 -> TiKV3: 发起apply确认
TiKV2 -> TiKV1: 进入apply
TiKV3 -> TiKV1: 进入apply
TiKV1 -> TiDB_Server: 收到一个apply成功反馈,即可反馈用户写入成功
TiDB_Server -> 用户: 反馈写入成功
@enduml
SQL事务的commit对应到这里的apply,这里的commited是指raft中记录上用户的数据更新了(多数据节点记录上用户的写入请求了)。
数据读取:
- tidb server解析SQL语句 -> 从pd获取对应key的tikv节点信息 ->
12 - 在AI时代该如何学习Java
在AI时代该如何学习Java,一个Goper如何快速转Java
在AI时代该如何学习Java,一个Goper如何快速转Java
12.1 - Go转Java万字总结, 要跨越哪些思维鸿沟
Goper如何快速转Java进行项目开发
主要介绍Go和java间的设计思想、工程目录结构、典型框架使用上的对比
Go转Java的设计思想对比
欲速则不达
先看思想差异!
Go的心智模式是过程式 + 轻量级面向对象 + 并发,从接需求开始,要识别结构体和关键方法,先实现小而美的功能点,再通过组合演进式地实现复杂功能。 Java不用说了,主要是以重量级OOP为主的玩法,要从需求中先找实体,加行为,定关系,用设计模式实现更复杂的业务。
不过现代Java也在拥抱轻量级设计, 而Go里也有设计模式,不过更倾于使用函数、闭包和通道等语言特性来解决。
先从直观语法上,总结有以下几种差异情况(只总结差异,不做优劣评价):
Go: 极简主义 - 少即是多, Go语法中有很多隐含的写法规则,在Java里则需要编写显式的修饰符(关键字)声明,比如某结构(类)中,首字母大写,是会暴露一个字段,在java则需要显示的使用public。
隐式规则与显式声明的碰撞
Go的"命名即契约"哲学:
// 大小写决定可见性
type User struct {
ID int // 公开
name string // 私有
}
func (u *User) GetName() string { // 公开方法
return u.name
}
func (u *User) setName(name string) { // 私有方法
u.name = name
}
Java语法层面的"显式声明"文化:
// 每个成员都需要明确修饰符
public class User {
private Long id; // 必须指定private
private String name; // 必须指定private
// 公开getter,需要显式public
public String getName() {
return this.name;
}
// 私有setter,需要显式private
private void setName(String name) {
this.name = name;
}
}
差异说明:
Go认为:代码即文档,命名应该自说明,过多的修饰符是噪声
- Go在“约定优于配置”的设计上主要体现在语法中,而在实际项目开发生态上,又是需要显式控制的写法,初学者可能会有隐形记忆负担。
- 但也由此衍生了很多标记tag的写法,如json tag,xml tag,gorm tag等等
- 这类工程需求,如数据库映射,验证,序列化等等,标记tag是由生态库来支持解决
- 仅在语法层面有编译时检查,Go的静态分析工具也在不断弥补运行时检查的不足
- Go的接口实现 "如果你能走起来像鸭子,叫起来像鸭子,那你就是鸭子",只要具备对应的方法行为,那么就认为实现了该接口
Java认为:强调明确性和类型安全,IDE和工具可以基于修饰符提供更好的支持
- 显式修饰符,如public,private,protected,static,final等等
- 与Go里tag可以对标Java里annotation注解的用法场景,不过后者注解是类型安全的
- 各种@注解满天飞,存在有框架级注解、持久化注解、验证注解、序列化注解等等。看似可以编译期间做显式检查,但有不小的学习成本,开发者需要熟悉不同注解的使用场景和配置选项
- Java的接口实现要"签字画押,明确契约",必须显示声明,如:implements,extends等等
- 虽然有非常优秀的“约定优于配置”的设计,过度了,就累赘了,现代的Java就在不断通过添加新特性来减少样板代码和注解复杂度。
"组合优于继承"原则
Go语言采用组合而非继承的设计哲学,通过结构体嵌入和接口组合实现代码复用。而Java的继承机制虽然提供了代码复用的便利性,但也引入了父类修改可能破坏子类的风险。两种设计哲学各有优劣:Go的组合更适合构建松耦合、可演进的系统,而Java的继承在构建具有清晰类型层次的大型应用时更有效率。
拥抱Java的显式性:
// 不要试图在Java中完全复制Go的隐式组合
// 接受Java需要更多样板代码的事实,体现了显式优于隐式的设计原则
// Go风格(隐式组合)
type Service struct {
*Logger // 嵌入指针,自动获得Logger的方法
*Metrics // 自动获得Metrics的方法
*Database // 自动获得Database的方法
}
// Java风格(显式但有更多控制)
class Service {
private final Logger logger;
private final Metrics metrics;
private final Database database;
// 显式构造器
public Service(Logger logger, Metrics metrics, Database database) {
this.logger = logger;
this.metrics = metrics;
this.database = database;
}
// 显式委托方法
public void log(String message) {
logger.log(message); // 明确的方法调用
}
}
思想总结
Go的组合哲学是"通过组合实现代码复用,而不是继承"。这种设计带来了:
- 灵活性:可以组合任意类型的任意方法
- 解耦:类型之间没有强制的层次关系
- 安全性:没有脆弱的基类问题
- 简洁性:语法简洁,自动委托
Java虽然支持继承,但现代Java开发也越来越倾向于"组合优于继承"。从Go到Java,需要:
- 接受更多的显式代码
- 使用设计模式(装饰器、代理、策略等)实现类似功能
- 利用Java 8+的接口默认方法
- 使用Lombok等工具减少样板代码
记住:Go是行为决定了类型,Java是类型决定了行为。理解这个核心差异,就能在两种语言间自如切换。
Go转Java的目录结构对比
工程范儿来了
工程化成熟度的体现,良好的目录结构不仅是代码组织方式,更是团队协作、质量保障和长期维护的基础。
标准项目布局
Go社区有一个被广泛接受的标准项目布局,虽然不是强制性的,但很多项目遵循。
my-go-project/
├── cmd/ # 应用程序入口目录
│ ├── app1/ # 每个可执行文件有自己的目录
│ │ ├── main.go # main函数
│ │ └── config.yaml # 该应用的配置
│ └── app2/
│ └── main.go
│
├── internal/ # 私有应用程序代码库
│ ├── pkg1/ # 项目内部包,外部项目不能导入
│ │ ├── service.go
│ │ └── service_test.go
│ └── pkg2/
│ ├── repository.go
│ └── repository_test.go
│
├── pkg/ # 公共库代码
│ ├── lib1/ # 可以被外部项目导入
│ │ ├── lib.go
│ │ └── lib_test.go
│ └── lib2/
│ ├── util.go
│ └── util_test.go
│
├── api/ # API定义
│ ├── protobuf/ # Protocol Buffer定义
│ │ └── user.proto
│ └── openapi/
│ └── swagger.yaml
│
├── web/ # Web静态资源
│ ├── static/
│ │ ├── css/
│ │ └── js/
│ └── templates/
│ └── index.html
│
├── configs/ # 配置文件模板或默认配置
│ ├── config.yaml.example
│ └── config.dev.yaml
│
├── scripts/ # 构建、安装、分析等脚本
│ ├── build.sh
│ ├── install.sh
│ └── release.sh
│
├── test/ # 额外的外部测试和测试数据
│ ├── integration/
│ └── testdata/
│
├── deployments/ # 部署配置
│ ├── docker/
│ │ ├── Dockerfile
│ │ └── docker-compose.yaml
│ └── kubernetes/
│ ├── deployment.yaml
│ └── service.yaml
│
├── docs/ # 文档
│ ├── design.md
│ ├── api.md
│ └── README.md
│
├── vendor/ # 依赖的副本(可选)
│
├── go.mod # 模块定义
├── go.sum # 模块校验和
├── .gitignore
├── LICENSE
└── README.md
Java标准布局(maven规范)
my-java-project/
├── src/
│ ├── main/ # 主源代码
│ │ ├── java/ # Java源代码
│ │ │ └── com/
│ │ │ └── example/
│ │ │ └── myapp/
│ │ │ ├── Application.java
│ │ │ ├── config/ # 配置类
│ │ │ ├── controller/ # 控制器层
│ │ │ ├── service/ # 服务层
│ │ │ │ ├── impl/ # 服务实现
│ │ │ │ └── UserService.java
│ │ │ ├── repository/ # 数据访问层
│ │ │ │ ├── entity/ # JPA实体类
│ │ │ │ ├── dao/ # DAO接口
│ │ │ │ └── mapper/ # MyBatis Mapper
│ │ │ ├── model/ # 数据传输对象
│ │ │ │ ├── dto/ # 请求/响应对象
│ │ │ │ └── vo/ # 视图对象
│ │ │ ├── exception/ # 异常类
│ │ │ └── util/ # 工具类
│ │ │
│ │ ├── resources/ # 资源文件
│ │ │ ├── application.yml # 主配置文件(启动端口、servlet配置之类的)
│ │ │ ├── application-dev.yml
│ │ │ ├── application-prod.yml
│ │ │ ├── logback-spring.xml
│ │ │ ├── mapper/ # MyBatis Mapper XML
│ │ │ ├── static/ # 静态资源
│ │ │ │ ├── css/
│ │ │ │ ├── js/
│ │ │ │ └── images/
│ │ │ └── templates/ # 模板文件
│ │ │ └── thymeleaf/
│ │ │
│ │ └── webapp/ # Web应用资源
│ │ ├── WEB-INF/
│ │ └── index.jsp
│ │
│ └── test/ # 测试代码
│ ├── java/
│ │ └── com/example/myapp/
│ │ ├── ApplicationTests.java
│ │ ├── controller/
│ │ ├── service/
│ │ └── repository/
│ └── resources/ # 测试资源
│ ├── application-test.yml
│ └── test-data.sql
│
├── target/ # 构建输出目录
│ ├── classes/
│ ├── test-classes/
│ ├── generated-sources/
│ ├── my-app.jar
│ └── surefire-reports/
│
├── pom.xml # Maven配置文件
├── mvnw # Maven包装器
├── mvnw.cmd
├── .mvn/ # Maven配置
│ └── wrapper/
│ └── maven-wrapper.properties
├── .gitignore
├── LICENSE
└── README.md
微服务架构对比
Go微服务典型布局
microservices-go/
├── api-gateway/ # API网关
│ ├── cmd/
│ ├── internal/
│ └── go.mod
├── user-service/ # 用户服务
│ ├── cmd/
│ ├── internal/
│ │ ├── handler/
│ │ ├── service/
│ │ └── repository/
│ ├── pkg/
│ └── go.mod
├── order-service/ # 订单服务
│ ├── cmd/
│ ├── internal/
│ └── go.mod
├── product-service/ # 产品服务
│ ├── cmd/
│ ├── internal/
│ └── go.mod
├── pkg/ # 共享包
│ ├── models/ # 共享模型
│ ├── utils/ # 共享工具
│ └── errors/ # 共享错误定义
├── deployments/ # 部署配置
│ ├── docker-compose.yaml
│ └── kubernetes/
├── scripts/
├── .gitignore
├── README.md
└── Makefile # 统一构建脚本
Java微服务典型布局(Spring Boot)
microservices-java/
├── discovery-server/ # 服务发现
│ ├── src/
│ └── pom.xml
├── api-gateway/ # API网关
│ ├── src/
│ └── pom.xml
├── user-service/
│ ├── src/main/java/com/example/user/
│ │ ├── UserApplication.java
│ │ ├── controller/
│ │ ├── service/
│ │ ├── repository/
│ │ ├── model/
│ │ └── config/
│ ├── src/main/resources/
│ ├── Dockerfile
│ └── pom.xml
├── order-service/
│ ├── src/
│ └── pom.xml
├── product-service/
│ ├── src/
│ └── pom.xml
├── common/ # 公共模块
│ ├── src/main/java/com/example/common/
│ │ ├── dto/
│ │ ├── exception/
│ │ └── utils/
│ └── pom.xml
├── config-server/ # 配置中心
│ ├── src/
│ └── pom.xml
├── deployments/
│ └── kubernetes/
├── .gitignore
├── README.md
└── pom.xml # 父POM,子模块可以继承配置
包/命名空间对比
Go的包导入路径
// 基于域名的导入路径
import (
"github.com/username/project/pkg/math"
"github.com/username/project/internal/database"
"mycompany.com/shared/utils"
)
// 包名与目录名相关,一目录一包命名
// 目录: /home/user/project/pkg/math
// 包声明: package math
特点:
- 包名简短,通常小写单数名词
- 导入路径反映代码仓库位置
- 不需要与目录结构完全对应
Java的包命名规范
// 反向域名 + 项目结构
package com.example.myapp.domain.user;
// 或分层结构
package com.example.myapp.controller;
package com.example.myapp.service;
package com.example.myapp.repository.entity;
package com.example.myapp.model.dto;
特点:
- 完全限定名,避免冲突
- 通常反映公司域名和项目结构
- 包名严格对应物理目录结构
构建和依赖管理对比
Go的构建和依赖管理
// Go: go.mod 文件
module github.com/mycompany/myapp
go 1.19 // 指定Go版本
require (
github.com/gin-gonic/gin v1.8.1
github.com/go-sql-driver/mysql v1.6.0
)
// 特点:
// 1. 语言版本在go.mod中指定
// 2. 依赖版本直接写在require中
// 3. 没有类似Maven的"属性变量"概念
// 4. 版本管理更简单直接
Go构建命令
go build ./cmd/app # 编译
go test ./... # 测试所有包
go mod tidy # 整理依赖
go mod vendor # 创建vendor目录
Java的构建管理
<!-- Maven: pom.xml -->
<project>
<!-- pom.xml的版本号,表明pom文件个字段含义的,不同于maven和项目的版本号 -->
<modelVersion>4.0.0</modelVersion>
<!-- 项目的基本信息坐标 -->
<groupId>com.example</groupId>
<artifactId>my-app</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<!-- 继承父pom.xml-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.0</version>
<!-- 不写relativePath时,会默认使用../pom.xml作为父pom.xml -->
<!-- 如下,为(空值)时,Maven 会跳过本地文件系统查找,直接从配置的远程仓库中下载父 POM -->
<relativePath/>
</parent>
<!-- properties 是 Maven 的"变量声明"区 -->
<properties>
<!-- 这里定义的都是"键值对",可以在整个pom.xml和代码中引用 -->
<java.version>11</java.version> <!-- 键: java.version, 值: 11 -->
</properties>
<dependencies>
<!-- Jar包依赖,包含Spring Boot的核心包依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<build>
<!-- 插件配置, 配置和管理mvn命令行的构建过程-->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>${java.version}</source> <!-- 引用上面properties的属性 -->
<target>${java.version}</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
构建命令(根据pom.xml中的build.plugins插件配置):
# 编译项目
mvn compile
# 运行应用,开发调试
mvn spring-boot:run
# 打包成可执行JAR
mvn package
# 清理构建
mvn clean
# 清理并重新下载依赖
mvn clean install
也有可以利用插件使用外部配置文件来配置maven构建参数,如version.properties或者application.properties。
<!-- 外部属性加载方式 -->
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>properties-maven-plugin</artifactId>
<version>1.1.0</version>
<executions>
<execution>
<phase>initialize</phase>
<goals>
<goal>read-project-properties</goal>
</goals>
<configuration>
<files>
<file>versions.properties</file>
</files>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
在后文的spring boot框架使用中,也会说明到使用外部独立properties或者yml文件来配置业务属性。
依赖管理总结
Go中内置了依赖管理机制,从GOPATH -> vendor到现在的GO modules机制, 而java当下典型的解决方案是需要用到Maven/Gradle工具的,并且Go.mod中没有类似Maven(properties)、Gradle(ext)的"属性变量"概念,一般是使用环境变量+Makefile变量的结合来解决同类场景,另外Maven属性查找是有优先级顺序的:
- 命令行参数 (-Dproperty=value) - 最高优先级
- settings.xml 中的
- 当前pom.xml 中的
- 父POM的
- Java系统属性
- 操作系统环境变量 (${env.VAR})
- Maven内置属性 - 最低优先级
典型框架使用对比
上文提到的Maven作为Java项目的构建工具,提供了强大的依赖管理能力,但依赖间的版本兼容性和配置细节仍需开发者操心。Spring Boot通过整合大量通用功能组件(以Bean形式,注解@启用)和提供自动化配置,极大地简化了项目搭建过程,结合IDE的脚手架生成能力,让开发者能更专注于业务开发。
相比之下,Go语言生态虽采用了不同的设计哲学,标准库功能强大,社区鼓励组合小而美的第三方库,但也使得开发者需要在 ORM、日志、认证等中间件通用组件方面进行更多自主选型和集成工作。虽然Go也有一些全功能框架(如 Goframe、Kratos),但尚未形成如 Spring 那样具有广泛影响力和企业级标准共识的生态系统。
web框架对比
Go的Gin框架示例
// main.go
package main
import "github.com/gin-gonic/gin"
func main() {
r := gin.Default() // 显式创建路由
// 中间件:显式添加
r.Use(Logger()) // 全局中间件
// 路由定义:简单直接
r.GET("/users", getUsers)
r.POST("/users", createUser)
r.GET("/users/:id", getUser)
auth := r.Group("/api", AuthMiddleware()) // 分组中间件
// 启动:一行代码
r.Run(":8080")
}
// 处理器:普通函数
func getUser(c *gin.Context) {
id := c.Param("id") // 手动获取参数,也有Bind()方法,需手动创建Go结构体接收
// 处理逻辑...
users := []User{{ID: id, Name: "Alice"}}
c.JSON(200, gin.H{"data": users})
}
Java的Spring Boot示例:
spring boot的应用,优先找src目录,应用入口默认在***Application.java**中。
@RestController // 默认返回JSON
@RequestMapping("/api/users") // 路由前缀
public class UserController {
@Autowired // 自动注入
private UserService userService;
// 通过注解声明路由
@GetMapping
public ResponseEntity<List<User>> getUsers() {
return ResponseEntity.ok(userService.getAllUsers());
}
@PostMapping
public ResponseEntity<User> createUser(@RequestBody User user) {
return ResponseEntity.status(201)
.body(userService.createUser(user));
}
@GetMapping("/{id}")
public ResponseEntity<User> getUser(@PathVariable Long id) { // 自动绑定参数
return ResponseEntity.ok(userService.getUserById(id));
}
}
// 主类 (Spring Boot 项目通常有一个名为 *Application 的入口类,
// 入口类里有一个main方法, 这个main方法其实就是一个标准的Java应用的入口方法)
// 最核心的启动类注解,下文细讲
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args); // 自动配置
}
}
@SpringBootApplication注解,充分体现了java生态中的约定优于配置,其本质上是一系列的注解组合,包括了:
@SpringBootConfiguration→ 类似Go的main()函数,告诉框架:"这是我的应用入口,从这里开始初始化"@ComponentScan→ 类似Go的init()函数 + 依赖注入,自动扫描注册项目中的组件(Controller、Service等),就像Go中通过import和init()自动注册各种处理器@EnableAutoConfiguration→ 类似Go的go build自动适配,根据classpath中的依赖,自动配置需要的Bean,比如:检测到MySQL驱动,自动配置DataSource,这就像Go的构建系统自动选择合适的平台实现一样
web框架设计方面,Go体现了开发者需要显式控制每个细节,框架轻量透明,而Java则体现了通过约定和自动配置减少开发者负担。
| 特性 | Go (Gin/Echo) | Java (Spring Boot) |
|---|---|---|
| 路由定义 | 方法链式调用 | 注解声明 |
| 路由匹配 | 精确匹配,也支持通配符 | 自动匹配,支持通配符 |
| 参数获取 | 显式调用 c.Param() | 注解自动绑定 @PathVariable |
| 分组路由 | 显式创建 Group | 类级别 @RequestMapping |
| 性能 | 极快,前缀树进行路由匹配 | 启动时构建,运行时匹配 |
ORM框架对比
Go的GORM是SQL友好,显式控制。
// GORM: 链式调用,类似SQL
type User struct {
gorm.Model
Name string
Email string `gorm:"uniqueIndex"`
Age int
}
// 查询
var user User
db.Where("age > ?", 18).
Where("name LIKE ?", "%张%").
Order("created_at desc").
First(&user)
// 关联查询 - 需要显式Preload
db.Preload("Orders").Preload("Profile").Find(&users)
// 原生SQL支持
db.Raw("SELECT * FROM users WHERE age > ?", 20).Scan(&users)
// 手动事务
tx := db.Begin()
if err := tx.Create(&user).Error; err != nil {
tx.Rollback()
return err
}
tx.Commit()
Java的Spring Data JPA是面向对象,声明式的。
// JPA实体
@Entity
@Table(name = "users")
@Data
@NoArgsConstructor
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@Column(unique = true)
private String email;
private Integer age;
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL)
private List<Order> orders; // 自动关联
@OneToOne(mappedBy = "user", cascade = CascadeType.ALL)
private Profile profile;
}
// Repository接口 - 声明式查询
public interface UserRepository extends JpaRepository<User, Long> {
// 方法名自动生成查询
List<User> findByAgeGreaterThan(int age);
List<User> findByNameContaining(String name);
// 自定义查询
@Query("SELECT u FROM User u WHERE u.age > :age ORDER BY u.createdAt DESC")
List<User> findAdults(@Param("age") int age);
// 分页查询
Page<User> findAll(Pageable pageable);
}
// 事务管理 - 声明式
@Service
@Transactional
public class UserService {
@Autowired
private UserRepository userRepository;
public User createUser(User user) {
return userRepository.save(user); // 自动事务
}
}
查询方式对比
| 特性 | Go (GORM) | Java (JPA/Hibernate) |
|---|---|---|
| 查询构建 | 链式方法调用 | 方法名推导、JPQL、Criteria |
| 关联加载 | 显式 Preload() | 自动或懒加载 FetchType |
| N+1问题 | 需手动避免 | 可配置 @BatchSize、JOIN FETCH |
| 缓存 | 无内置 | 一级/二级缓存 |
| 乐观锁 | 手动实现 | @Version 自动管理 |
| 审计 | 结构体标签 | @CreatedDate 等注解 |
注:N+1问题是数据库查询中一个经典的性能陷阱 1次查询(获取所有文章) N次查询(每篇文章都要单独查一次评论) 总共:1 + N 次数据库查询
依赖注入对比
Go的依赖注入模式是显式声明,通过函数参数传递。
// 1. 手动依赖注入(最常用)
type UserService struct {
repo UserRepository
cache Cache
logger *log.Logger
}
func NewUserService(repo UserRepository, cache Cache, logger *log.Logger) *UserService {
return &UserService{repo: repo, cache: cache, logger: logger}
}
// 2. 选项模式(Builder模式)
type UserService struct {
repo UserRepository
cache Cache
logger *log.Logger
}
type Option func(*UserService)
func WithCache(cache Cache) Option {
return func(s *UserService) { s.cache = cache }
}
func NewUserService(repo UserRepository, opts ...Option) *UserService {
s := &UserService{repo: repo}
for _, opt := range opts {
opt(s)
}
return s
}
// 使用
service := NewUserService(repo, WithCache(redisCache))
Java的依赖注入模式是隐式声明,通过注解自动注入。
// 1. 构造器注入(Spring推荐)
@Service
public class UserService {
private final UserRepository userRepository;
private final Cache cache;
private final Logger logger;
@Autowired
public UserService(UserRepository userRepository,
Cache cache,
Logger logger) {
this.userRepository = userRepository;
this.cache = cache;
this.logger = logger;
}
}
// 2. Setter注入
@Service
public class UserService {
private UserRepository userRepository;
@Autowired
public void setUserRepository(UserRepository userRepository) {
this.userRepository = userRepository;
}
}
依赖注入部分的对比,可以看出来,Go的理念是"代码应该清晰表达意图,不依赖魔法",Java生态的理念则是"框架处理基础设施,开发者专注业务逻辑"。
配置管理对比
// 使用Viper, Go生态中最流行的配置管理库
import "github.com/spf13/viper"
func LoadConfig() (*Config, error) {
viper.SetConfigName("config")
viper.SetConfigType("yaml")
viper.AddConfigPath(".")
// 默认值
viper.SetDefault("server.port", 8080)
viper.SetDefault("server.timeout", 30)
// 环境变量支持
viper.AutomaticEnv()
viper.SetEnvPrefix("APP")
viper.BindEnv("server.port", "APP_SERVER_PORT")
// 配置文件
if err := viper.ReadInConfig(); err != nil {
if _, ok := err.(viper.ConfigFileNotFoundError); ok {
log.Println("使用默认配置")
} else {
return nil, err
}
}
var config Config
if err := viper.Unmarshal(&config); err != nil {
return nil, err
}
return &config, nil
}
// 结构体映射
type Config struct {
Server ServerConfig `mapstructure:"server"`
Database DatabaseConfig `mapstructure:"database"`
Redis RedisConfig `mapstructure:"redis"`
}
type ServerConfig struct {
Port int `mapstructure:"port"`
Timeout int `mapstructure:"timeout"`
Env string `mapstructure:"env"`
}
Java的配置
// 1. application.yml
server:
port: 8080
timeout: 30s
spring:
datasource:
url: jdbc:mysql://localhost:3306/db
username: root
password: secret
redis:
host: localhost
port: 6379
app:
name: myapp
version: 1.0.0
// 2. @ConfigurationProperties
@Configuration
@ConfigurationProperties(prefix = "app")
@Data
public class AppProperties {
private String name;
private String version;
private List<String> features = new ArrayList<>();
}
// 3. @Value注解
@Component
public class MyComponent {
@Value("${server.port}")
private int port;
@Value("${app.name:defaultApp}") // 默认值
private String appName;
@Value("#{'${app.features}'.split(',')}")
private List<String> features;
}
总计起来,Go (Viper):你需要告诉它每一步做什么,它精确执行,Java (Spring Boot):你告诉它想要什么,它自动完成所有细节。
任务调度
Go的定时任务可以使用原生的time.Tick和time.After函数实现。
// 1. 原生goroutine + ticker
func scheduleTask() {
ticker := time.NewTicker(1 * time.Hour)
defer ticker.Stop()
for {
select {
case <-ticker.C:
doTask()
case <-stopChan:
return
}
}
}
// 2. 使用cron库
import "github.com/robfig/cron/v3"
func main() {
c := cron.New()
// 添加任务
c.AddFunc("0 0 * * *", cleanUpTask) // 每天午夜
c.AddFunc("*/5 * * * *", heartbeatTask) // 每5分钟
c.AddFunc("@hourly", hourlyTask) // 每小时
c.AddFunc("@every 1h30m", complexTask) // 每1.5小时
c.Start()
defer c.Stop()
// 等待
select {}
}
// 3. 分布式任务调度 (Machinery)
import "github.com/RichardKnop/machinery/v1"
import "github.com/RichardKnop/machinery/v1/config"
func main() {
// 配置
cnf := &config.Config{
Broker: "redis://localhost:6379",
DefaultQueue: "machinery_tasks",
ResultBackend: "redis://localhost:6379",
}
// 创建服务器
server, err := machinery.NewServer(cnf)
if err != nil {
panic(err)
}
// 注册任务
server.RegisterTask("add", Add)
server.RegisterTask("multiply", Multiply)
// 启动worker
worker := server.NewWorker("worker1", 10)
go worker.Launch()
// 发送任务
signature := &tasks.Signature{
Name: "add",
Args: []tasks.Arg{
{Type: "int64", Value: 1},
{Type: "int64", Value: 2},
},
}
asyncResult, err := server.SendTask(signature)
if err != nil {
panic(err)
}
result, err := asyncResult.Get(time.Duration(time.Millisecond * 5))
if err != nil {
panic(err)
}
}
Java的定时任务可以使用Spring的@Scheduled注解实现。
// 1. Spring Scheduled
@Component
public class ScheduledTasks {
// 固定延迟
@Scheduled(fixedDelay = 5000)
public void taskWithFixedDelay() {
// 任务完成5秒后再次执行
}
// 固定速率
@Scheduled(fixedRate = 5000)
public void taskWithFixedRate() {
// 每5秒执行一次
}
// Cron表达式
@Scheduled(cron = "0 0 9-17 * * MON-FRI")
public void officeHoursTask() {
// 工作日9点到17点每小时执行
}
// 初始延迟
@Scheduled(initialDelay = 1000, fixedRate = 5000)
public void taskWithInitialDelay() {
// 启动后延迟1秒,然后每5秒执行
}
}
// 2. Quartz集成
@Configuration
public class QuartzConfig {
@Bean
public JobDetail jobDetail() {
return JobBuilder.newJob(MyJob.class)
.withIdentity("myJob", "group1")
.storeDurably()
.build();
}
@Bean
public Trigger trigger() {
return TriggerBuilder.newTrigger()
.forJob(jobDetail())
.withIdentity("myTrigger", "group1")
.withSchedule(CronScheduleBuilder.cronSchedule("0/5 * * * * ?"))
.build();
}
}
@Component
public class MyJob implements Job {
@Override
public void execute(JobExecutionContext context) {
// 执行任务
}
}
// 3. 分布式任务 (XXL-Job/Elastic-Job)
@XxlJob("demoJobHandler")
public ReturnT<String> demoJobHandler(String param) {
// 分布式任务
return ReturnT.SUCCESS;
}
核心差异一句话总结的话,Go生态强调的是“你构建调度器,精确控制每个细节”,Java则更强调的是“你声明任务,框架负责调度执行”。
单元测试、API文档、可观测、异常处理等等都是常见的开发需求,Go和Java都有对应的解决方案,此处不表。
总结
通过对Go和Java在设计思想、工程目录结构、典型框架使用三个维度的深入对比,我们可以提炼出两种语言生态在工程化理念上的本质差异:
核心差异的哲学本质
Go是"显式控制"的设计哲学:语言设计强调开发者对每个细节的精确把控,框架轻量透明,代码即文档。通过组合、接口隐式实现、命名即契约等机制,在保持简洁的同时提供足够的灵活性。这种设计让Go特别适合构建高性能、高可靠性的基础设施和微服务。
Java是"约定优于配置"的工程哲学:通过注解、AOP、自动配置等机制,将复杂的基础设施问题抽象为简单的开发体验。Spring Boot为代表的框架让开发者能够专注于业务逻辑,框架负责处理底层复杂性。这种设计让Java在构建大型企业级应用时具有显著优势。
思维转换的关键点
从Go转向Java,开发者需要完成以下几个关键思维转换:
- 从隐式到显式:Go中"命名即契约"的隐式规则(如首字母大小写决定可见性)在Java中需要显式的修饰符和注解来表达。接受Java的样板代码,理解"显式优于隐式"的设计原则。
- 从组合到分层:Go的组合哲学在Java中更多体现为分层架构(Controller-Service-Repository)和设计模式的运用。理解Java的OOP本质,学会用接口、抽象类和设计模式构建可维护的系统。
- 从手动控制到自动配置:Go中需要手动管理依赖注入、配置加载、路由定义等,而Java(尤其是Spring Boot)通过约定和自动配置大幅简化这些工作。学会信任框架,理解"不要重复造轮子"的工程智慧。
- 从轻量级到全功能:Go标准库功能强大但相对基础,需要开发者自行选型和集成第三方库;Java生态提供了完整的解决方案栈。理解Java生态的复杂性,学会在丰富的工具链中选择合适的组件。
实用建议
对于Go开发者转向Java
- 优先掌握Spring Boot的核心概念和自动配置机制
- 从简单的CRUD应用开始,逐步理解分层架构的价值
- 学会使用IDE(如IntelliJ IDEA)的强大功能,弥补Java样板代码的繁琐
- 重视类型安全和接口设计,这是Java OOP的核心
对于Java开发者学习Go
- 摒弃"必须有框架"的思维,从标准库开始构建应用
- 理解组合优于继承的设计哲学,避免过度设计
- 重视代码简洁性和可读性,Go的美学在于"少即是多"
- 学会使用Go Modules管理依赖,理解Go的构建哲学
未来趋势
两种语言的生态正在相互借鉴和融合:
- Go生态正在成熟:随着Go 1.18+泛型的引入,以及像Kratos、GoFrame等全功能框架的兴起,Go在大型应用开发方面的能力不断增强,但仍保持"显式控制"的核心哲学。
- Java生态正在轻量化:Spring Boot 3.x、Quarkus、Micronaut等框架通过GraalVM原生编译、快速启动等特性,让Java应用更轻量、更云原生,同时保留其企业级能力。
- 多语言架构成为常态:在现代云原生架构中,Go和Java往往共存于同一技术栈:Go负责基础设施、CLI工具、高性能服务;Java负责核心业务逻辑、复杂事务处理。理解两种语言的优劣势,能够在正确的场景选择正确的工具。
语言只是工具,工程化才是本质。无论是Go的"显式控制"还是Java的"约定优于配置",最终目标都是构建高质量、可维护、可演进的软件系统。
12.2 - AI时代下,Java该如何起手项目开发
结合人工智能在软件工程领域大行其道的当下,该如何快速开启Java项目的设计开发
30多年来,开发者工具层面终于出现了革命者,本文主要结合人工智能在软件工程领域大行其道的当下,针对从零开始和迭代已有项目,介绍如何快速开启Java项目的设计开发。
最近常听到一句话,AI不会替代你,但熟练使用AI的人可以轻松干废你。 初听有点儿耸人听闻,实际却在发生中.... 甚至斯坦福大学最近也开设了CS146S课程, 要求必须使用AI完成开发任务,作业是提交完成开发任务的提示词prompt。专门教授如何将大模型和AI工具(如编程智能体、AI IDE)集成到软件开发流程中,从而大幅提升开发者的生产力,并探讨了现代软件工程师的角色演变。课程大纲如下:

工欲善其事必先利其器
传统开发,必备神器IDEA
下图是2025.3版本,安装包大小1G,包括java生态的大量工具插件,还内置了教学引导,默认给30天的免费旗舰试用期。
导引学习,主要介绍一些快捷键(包括any搜索、补全建议、重构)和调试技巧等。
- Ctrl+Shift+A或者两次Shift按键,触发anything search。
- Alt + Enter, 万能修复/提示
- Ctrl + Shift + Space,智能代码补全
- Ctrl + Alt + L,代码格式化
传统IDE中,补全是当初能让其迅速普及开的功能之一,而调试也是另一个极好的功能。在现代AI IDE中,调试似乎也不需要了,直接贴错误日志,就自动开始debug纠错了。
使用AI开发的现状
当下主流的使用AI开发模式有3种基本形态:
一种是传统IDE + 编程插件助手,代表有Lingma、Continue等,是属于渐进式拥抱AI辅助开发,从而提高生产力的方式。
另一种是基于开源IDE打造的AI原生IDE, 提供更沉浸式的AI编程体验,由AI自主完成分析、设计、编码乃至测试的完整流程,一般需要订阅收费。
- 国外:Cursor(基于VS Code)
- 国内:Trae.CN(字节)、CodeBuddy(腾讯),Qoder(阿里.新加坡团队)
还有一种终端工具,代表是Claude Code、Codex CLI等,可以灵活集成到以上两种模式和其他第三方CI/CD协作流水线中
现在市场参与者,基本都在布局各形态的开发场景,本文发稿时,通义lingma也在公测IDE了,CodeBuddy已实现插件、IDE、CLI三端全形态覆盖。
年初我个人也结合开源vscode+roocode插件,开发过一款自己的IDE,叫aide,基本功能也都具备,后面有时间可以整理发出来一篇手把手打造自己的AI原生IDE。

不过github Copilot在国内市场才是比较可惜的,背靠微软(VS生态),手里有github,竟然在市场上,没有国外初创企业Cursor等的声势浩大。
这几种形态,反映了一个演进方向: 将AI集成到开发工具 ====> 将开发工具集成到AI中。人在其中的动手参与度逐步降低,后者看上去是最理想的终极形态,合理设置后,可以让AI把整个软件交付的全流程(需求分析->设计->编码->测试->部署上线)自动完成。
不过这里不应该存在谁更好的说法,最终要看你的团队运作模式,是单人全栈还是严格‘瀑布模式’下的团队模式,毕竟康威定律还在生效(技术问题的背后,往往是人的问题和组织问题)。这类AI原生IDE现在也基本支持个人版和企业版了,不过从业内的实践来看,在单人全栈模式下,AI原生IDE的优势会更明显。
由于本人工作行业限制,接触最多的是lingma,不过为了客观对比更高阶的形态,这里以Trae.CN为例
安装包大小204M,内置前端工具链,如涉及其他技术栈,需要自行安装插件。 支持两种模式(IDE和solo模式),就是前面提到的IDE+插件助手模式和AI原生IDE的形态。
AI原生IDE,相对传统IDE,最大的区别是在软件工程中的参与阶段左移了,从需求分析开始就可以介入了,并且以AI为主导推理,自动调度集成MCP工具来推进工作。
Vibe Coding 氛围/AI结对编程
零开项目(避免重复造轮子)
java生态已经非常丰富,几乎每个领域都有对应成熟、经过验证的开源项目,遵循专业的事情找专业的工具干的原则(寻找轮子),避免让AI从零开始重复造轮子。
鉴于LLM的工作原理,预测Token,让AI从零开始重复造轮子,这是血亏的实践结论。。。应该利用已有成熟库,喂文档,进入迭代阶段。 当前最佳SOTA实践是Claude的Skills攻略,此处不介绍,如涉及复杂项目可考虑(个人还没试过)。
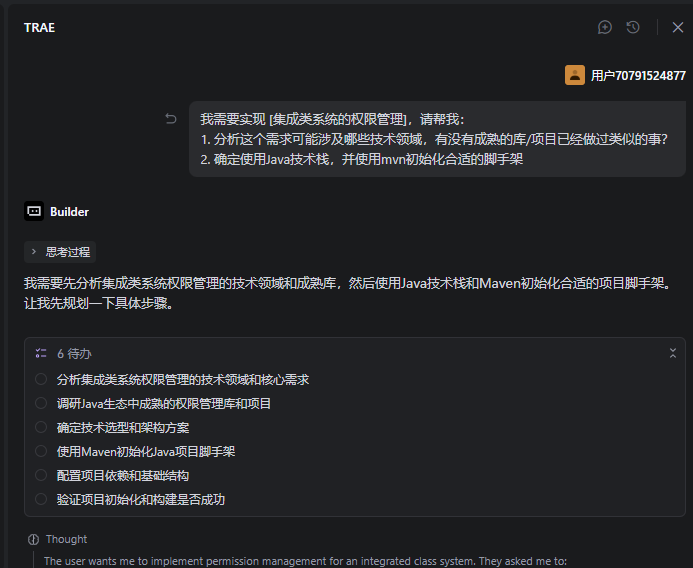
推荐先要根据项目需求场景,直接驱动builder使用成熟脚手架或者传统IDE初始化一个项目基础架构。整理提示模版如下:
我需要实现 [集成类系统的权限管理],请帮我:
1. 分析这个需求可能涉及哪些技术领域,有没有成熟的库/项目已经做过类似的事?
2. 确定使用Java技术栈,并使用mvn初始化合适的脚手架
需要提前安装配置好JDK和Maven环境,此处不表。
如果公司有对应的研发规范,推荐使用rules规则,将提示模版作为rules规则,让AI根据规则进行架构设计选型。
迭代存量项目
打开已有项目的根目录,会自动判断项目技术栈,并推荐安装相应的插件。
IDE模式下,内置了4中智能体
大多数情况下,builder就可以完成开发任务,要熟悉存量项目架构设计的话可以使用chat模型。chat模式下,可以询问代码算法细节,项目依赖用法等。
建议先在buidler模式下,自动生成团队规范。提示词如下
生成该项目的一个团队规范,存放于.trae\rules\project_rules.md文件中
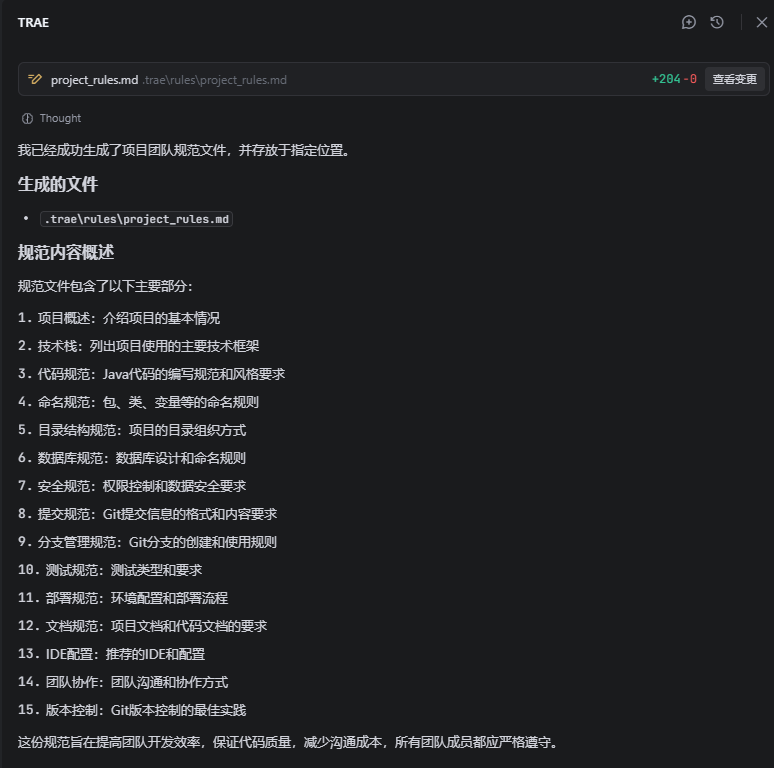
一定要确认自动生成规范是否有误并合理。
迭代项目时,让AI根据规则进行架构设计选型和代码编写。 未完...后面单独开章分享。
总结
要想真正在AI原生IDE中上手生产级系统开发,还是要掌握一些基础的编程技能,如数据结构、算法、设计模式、软件工程等等。
本文开头提到的CS146S课程,也是要求学生必须具备扎实的编程经验,才能报名的。不然,一是不知道如何让AI更好的替我们工作产出(prompt该如何写),二是不知道AI的产出是否存在隐患,很快就会进入AI“屎山”代码中,是你真的会看不懂一小时前的某段代码逻辑意图... 至少当下,会因为AI的易得性反而更容易欠下技术债务。软件还是要讲究可维护性的,不过话又说回来,不需要后续维护的,讲究快速原型的场景,确实是极好的。
AI协同并不简单,让开发人员最讨厌的文档编写,直接上升到了第一公民,变成面向文档编程了。不过这个领域还在快速发展中,但人与AI协同开发的共识,个人比较认可的原则总结如下:
- 人来负责“规划”,AI 负责“执行”
- 绝不提交自己不理解的代码
- 避免重复造轮子
- 小步迭代,持续清理
参考资料:
- Vibe Coding 指南 - https://github.com/tukuaiai/vibe-coding-cn
- “AI 辅助编程”第一案 - https://zhuanlan.zhihu.com/p/1984901894875935875
12.3 - Goper直接撸java代码,真是操碎了心,tips总结①
Java Tips总结
Java发展的这些年,为了复杂大型项目的工程实践能傻瓜落地,真是封了一层又一层啊,C/C++型选手转过来,会感觉各种看不透,总结了一些tips,尽量追根问底,分享给大家。
@SpringBootApplication 注解
java spring项目,第一个看到的基本就是这个注解,只能加到main方法所在的主类上,标识这是一个Spring Boot应用程序的main入口类。
@(注解)的本质是给代码打标签,告诉需要处理注解的工具或框架: 这里的代码需要特殊处理。
“@SpringBootApplication”注解,是个组合注解,是表示要在程序启动运行阶段被特殊处理的(其实现完全依赖于Java的反射机制),是spring框架的核心机制,依靠Spring容器的运行时处理能力,体现了「约定优于配置」的设计思想。
没点儿Java经验,「约定优于配置」的设计思想,会让学习成本增加,但是在大型项目中,会让开发效率大大提高。 spring 容器的运行时处理能力,是实现「约定优于配置」的关键。
Spring 容器
spring 容器是一个IoC容器(简单理解为一个对象工厂),用于管理应用程序中的Bean对象。
Bean的生命周期包括:实例化、依赖注入、初始化、使用、销毁。 依赖注入是指在运行时,通过容器自动将Bean的依赖对象注入到Bean中。 初始化是指在Bean实例化后,调用Bean的初始化方法。 使用是指在Bean初始化后,通过容器获取Bean实例,调用其方法。 销毁是指在应用程序关闭时,调用Bean的销毁方法。
简单来说:
- 你写好代码,贴上标签(注解)
- 容器帮你管理这些代码(Bean)
- 你需要什么,容器就给你什么(依赖注入)
为什么要使用 Spring 容器?
理由有一堆,还都是高大上的那种....
拿用户注册功能对比,举例说明,对比「不用Spring容器」和「用Spring容器」的代码差异,直观展示Spring容器的价值:
场景:用户注册功能(需要3层结构)
- Controller :接收注册请求
- Service :处理注册业务逻辑(密码加密、保存用户)
- Repository :操作数据库(保存用户信息)
方式1:不用Spring容器 → 传统Java开发
// 1. Repository层:操作数据库
public class UserRepository {
public void save(User user) {
System.out.println("保存用户到数据库:" + user.getName());
}
}
// 2. Service层:业务逻辑
public class UserService {
// 必须手动创建依赖对象 → 「自己new」,初始化省略..
private UserRepository userRepository = new UserRepository();
public void registerUser(User user) {
// 密码加密(业务逻辑)
user.setPassword(encryptPassword(user.getPassword()));
// 调用Repository保存
userRepository.save(user);
}
private String encryptPassword(String password) {
return "加密后的密码:" + password;
}
}
// 3. Controller层:接收请求
public class UserController {
// 必须手动创建依赖对象 → 「自己new」
private UserService userService = new UserService();
// 可以改进为接收参数
public void handleRegisterRequest(String name, String password) {
User user = new User();
user.setName(name);
user.setPassword(password);
userService.registerUser(user);
}
}
// 4. 启动类:手动创建所有对象
public class App {
public static void main(String[] args) {
// 必须手动创建所有层的对象 → 「自己管理依赖」
UserController controller = new UserController();
// 调用注册接口
controller.handleRegisterRequest("张三", "123456");
}
}
有点儿偏面向过程的开发思路,需要自己管理各层依赖对象的创建初始化 :
- 必须手动 new 所有对象,代码冗余
- 依赖关系硬编码(UserService直接依赖UserRepository的具体实现)
- 修改依赖时有可能需要修改所有相关代码(比如把UserRepository换成Redis实现)
- 无法集中管理对象生命周期
方式2:用Spring容器 → 依赖注入开发
// 1. Repository层:用@Repository标记,告诉容器「UserRepository类是要管理的Bean对象」
@Repository
public class UserRepository {
public void save(User user) {
System.out.println("保存用户到数据库:" + user.getName());
}
}
// 2. Service层:用@Service标记,@Autowired让容器自动注入依赖
@Service
public class UserService {
// 容器自动注入UserRepository → 「不用自己new」,配置已初始化
@Autowired
private UserRepository userRepository;
public void registerUser(User user) {
// 专注于业务逻辑(密码加密)
user.setPassword(encryptPassword(user.getPassword()));
userRepository.save(user);
}
private String encryptPassword(String password) {
return "加密后的密码:" + password;
}
}
// 3. Controller层:用@RestController标记,@Autowired自动注入Service
@RestController
public class UserController {
// 容器自动注入UserService → 「自动解决依赖」
@Autowired
private UserService userService;
@PostMapping("/register")
public String registerUser(@RequestBody User user) {
// 专注于处理请求,不用关心Service怎么来的
userService.registerUser(user);
return "注册成功";
}
}
// 4. 启动类:用@SpringBootApplication标记,容器自动创建所有对象
@SpringBootApplication
public class App {
public static void main(String[] args) {
// 一行代码启动 → 容器自动处理所有对象创建和依赖
SpringApplication.run(App.class, args);
}
}
具体价值体现 1. 价值1:不用自己new对象
- 价值1:不用自己new对象
- 传统方式 :每个类都要手动 new 依赖对象,并自己管理参数初始化
- Spring方式 :只需要用 @Service / @Repository 标记,容器自动创建,并配合其他注解可自动配置参数。
- 例子 : UserService 不用写 new UserRepository() ,容器会自动创建并注入
- 价值2:自动解决依赖
- 传统方式 :依赖关系硬编码,修改时要改所有相关代码
- Spring方式 : @Autowired 自动找到并注入(嵌入)合适的对象
- 例子 :如果把 UserRepository 换成Redis实现,只需要给Redis实现类加 @Repository ,不需要修改 UserService 代码
- 价值3:专注业务逻辑
- 传统方式 :花大量时间管理对象创建和依赖
- Spring方式 :只需要关心业务逻辑(如密码加密、用户验证)
- 例子 : UserService 只需要写 registerUser 的业务代码,不用关心 UserRepository 怎么来的
spring 启动过程
回到开头提到的spring应用中常遇到的第一个注解,会出现在主类上,“@SpringBootApplication”注解,标识这是一个Spring Boot应用程序的main入口类。
“@SpringBootApplication”注解,包含了以下3个注解:
@SpringBootConfiguration: 标识这是应用的主配置类(入口),是@Configuration的派生注解,提供了Spring Boot特定的配置语义,确保配置类能被正确识别和处理,优先级说明:默认配置 → 自动配置 → 外部配置(application.yml) → 手动配置(@Configuration)。
@EnableAutoConfiguration: 启用Spring Boot的自动配置机制。
- 自动扫描 classpath 下所有
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports文件(Spring Boot 2.7+) - 根据pom中的配置的依赖包、条件配置类等信息,自动配置相应的Bean(比如数据源、Web MVC配置等)。
- 另外会看application.yml配置文件中的属性,覆盖默认配置。举例:修改Tomcat默认端口为9090。
# application.yml
server:
port: 9090 # 覆盖默认的 8080 端口
spring:
datasource:
url: jdbc:mysql://localhost:3306/yudao
username: root
password: 123456
- Profile多环境支持
- 可以根据不同的环境(如开发、测试、生产),加载不同的配置文件(如application-dev.yml、application-test.yml、application-prod.yml)。
- 可以通过spring.profiles.active属性指定当前激活的环境,默认是default环境。
- @ComponentScan: 开启组件扫描,Spring Boot会自动扫描主类所在的包及其子包,重点找到使用了@Controller、@Service、@Repository等注解的类,并将这些Bean对象注册到Spring容器中。
- 支持通过basePackages参数设置,指定要扫描的包名,控制扫描范围,灵活组织应用的功能。
经过以上3个隐含注解的协同处理,程序启动完成,会进入运行状态,等待接收外部请求。
示例:
/**
* Spring Boot应用程序的主启动类
*
* @SpringBootApplication 是一个组合注解,包含以下三个核心功能:
* 1. @SpringBootConfiguration: 标识这是一个Spring Boot应用的主配置类
* 2. @EnableAutoConfiguration: 启用Spring Boot的自动配置机制
* 3. @ComponentScan: 自动扫描当前包及其子包下的组件(如@Controller、@Service、@Repository等)
*
* 这个注解告诉Spring Boot框架:这是一个Spring Boot应用程序的入口点
*/
@SpringBootApplication
public class ServerApplication {
/**
* 应用程序的主入口方法
*
* 当JVM启动时,会首先执行这个main方法
* 该方法负责启动整个Spring Boot应用程序
*
* @param args 命令行参数,可以在启动时传入配置参数
* 例如:--server.port=8081 或 --spring.profiles.active=dev
*/
public static void main(String[] args) {
/**
* SpringApplication.run() 方法执行以下关键操作:
* 1. 创建Spring应用上下文(ApplicationContext)
* 2. 启用自动配置(根据classpath中的依赖自动配置Bean)
* 3. 启动内嵌的Web服务器(如Tomcat、Jetty等)
* 4. 扫描并注册所有使用Spring注解的组件
* 5. 启动完成后,应用程序进入运行状态,等待HTTP请求
*
* 参数说明:
* - ServerApplication.class: 主配置类,Spring Boot会从这个类所在的包开始扫描组件
* - args: 命令行参数,用于覆盖默认配置
*
* 返回值:ConfigurableApplicationContext对象,代表整个Spring应用上下文
* 可以用于获取Bean、关闭应用等操作
*/
SpringApplication.run(ServerApplication.class, args);
}
}
这个过程体现了spring boot生态的核心价值 - 配置自动化,开发人员可以通过pom引入下依赖包(内部包也一样),然后直接改改yml配置,就可以轻松写出生产级的代码了。
SpringBootApplication注解工作的机制中,还有不少细节,属于用到了可以现查资料的知识,此处先不展开。 spring框架还有很多AOP、事务管理等其他优势,此处先不展开。
lombok
解决Java样板代码的利器,通过**@注解**的方式,在编译期自动生成对应的代码,减少了样板代码的编写,提高了开发效率。
解决了哪些样板代码的编写? 比如:getter/setter、toString、equals、hashCode等。这些方法在大多数Java类中都需要,但是编写逻辑高度重复啰嗦,通过lombok注解,就可以自动生成这些代码,减少了开发人员的机械工作量。举例:
@Data // @Data组合注解,自动为该类生成getter/setter/toString/equals/hashCode等方法,节省了约50行左右的代码量。
// 相当于以下注解组合
// @Getter、@Setter、@ToString、@EqualsAndHashCode等
public class User {
private Long id;
private String name;
private Integer age;
}
为什么每个Java类都需要这些方法 ?
因为这些方法是Java类的基础(所有类都直接或间接的继承了Object类),没有它们,大多数Java类就不能正常工作。
// 所有类都继承 Object
public class User { // 隐式继承 Object
// 自动拥有 Object 的方法:toString(), equals(), hashCode() 等
}
比如:
- 没有getter/setter方法,就不能通过对象的属性来访问和修改属性值,Java封装思想的具体实现。
- 没有toString方法,就不能通过System.out.println()方法来打印对象的信息。
- 没有 equals 方法,虽然仍然可以使用equals方法(继承自Object),只是比较的是引用相等性,不能用于比较对象内容是否相等。
- 没有 hashCode 方法,就不能将对象存储在HashSet、HashMap等集合中。
Map<User, String> map = new HashMap<>();
User user = new User();
map.put(user, "value"); // 需要拥有正确的 hashCode() 和 equals()
Set<User> set = new HashSet<>();
set.add(user); // 同样需要正确的 hashCode() 和 equals()
确保了 Java 中所有对象都具有统一的基本行为,也是哈希集合(如 HashMap、HashSet)等功能的基础。