解读SRE行业2025调查报告
报告统计源说明
报告所依据的SRE调查,是从2024年7月开始,花了6周的时间,收到来自全球各地、涵盖各类可靠性岗位及职级的301份有效回复。
调查者大部分源自美欧中,国内有墙的情况下,还能有这等占比,其实中国占比很高了。
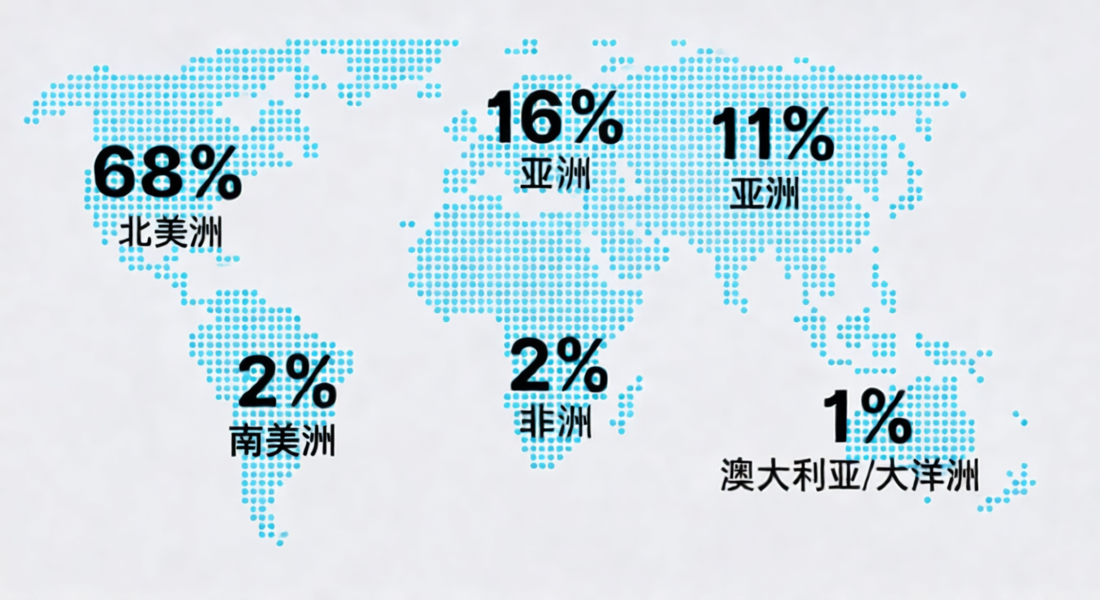
全球地域分布情况
来源:The SRE Report 2025, Catchpoint
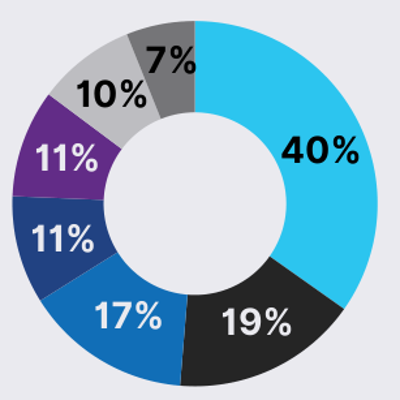
其中企业分类性质的占比如下: 企业类型占比
来源:The SRE Report 2025, Catchpoint
- 40%,技术平台或“即服务”提供商,(钉钉或者Salesforce这类)
- 19%,其他(制造业、医疗等)
- 17%,金融服务
- 11%,零售/电子商务
- 11%,大型集团:跨多个领域运营
- 10%,高等教育
- 7%,政府
公司规模占比,上千人的公司占比超过51%。 企业规模占比
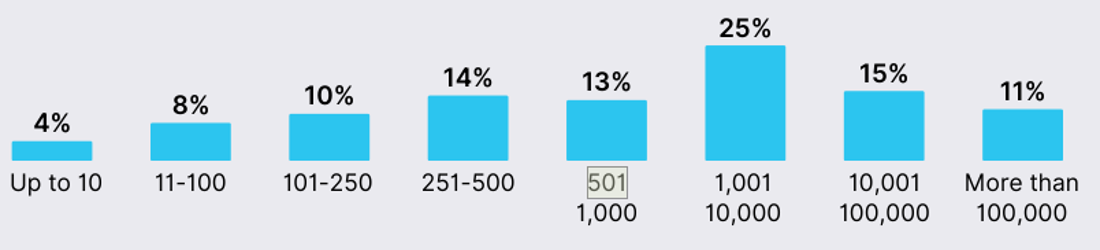
来源:The SRE Report 2025, Catchpoint
趋势观点
报告揭示了几个核心趋势,我结合自身经历用大白话来解释一下
慢即宕机(Slow is the New Down)
这个观点讲的是,一个服务响应很慢和完全宕机的危害一样大。想象一下,在网购时页面转圈十几秒才加载出来,你很可能就直接关掉走人了。所以,性能好坏直接关系到用户体验和业务收入。
性能优化,首屏响应之类的词汇,其实在国内也早有相应的需求讨论,这里将其上升到了宕机的危害程度,调查中也有53%的人认可这一说法,另一个有意思的是,44%人认为还应该把这一指标作为SLO目标。
SLO目标:SLO(Service Level Objective,服务水平目标) 简单来说,就是你为一项服务设定的、可量化的可靠性目标。它不再是以往被动运维的底线保障思维,如保障系统可用性几个9的承诺,而是一个具体、可测量的指标,用于明确回答:“对用户而言,这个服务怎样才算是‘真好用’” 例如,一个视频流服务的SLO可以是:“99.9%的用户请求应在1秒内得到成功响应。” 类似的还有,首页网页加载时间小与200ms
这里面,其实是SRE运维关注点,从应用可用性到好用的转变。从慢即是宕机的观点出发,优化影响SLO指标,也可算是为SRE技术人员绩效评定的一个补充。因为>SLO提升了多少,是比较容易讲清楚,带了更多的业务收益价值。
当下,判断一个应用服务是“慢到难以忍受”还是“完全不可用”,两者之间的界限不是很重要。无论是用户因页面卡顿而放弃支付购物车中的商品,还是分布式系统(微服务)因响应超时而触发故障转移,其最终结果是一致的——服务实质上已经失效了。
这一点其实在实践过微服务、云原生架构的人,应该也关注到了,比如要:
- 解耦架构:将同步的实时处理与异步的后台任务分离,避免非关键路径拖慢核心用户体验;
- 韧性降级:在资源紧张或负载过高时,弹性缩减非核心功能,以保障基础服务可用,而非直接崩溃。
同样也影响了处理数据IO的思路:
- 通过预计算、多级缓存和高效索引,加速高频访问路径;
- 从磁盘 I/O、内存管理、CPU 计算到网络传输,每一层都致力于最小化延迟,确保数据流经最小路由跳数就可达目的地。
运维理念也在随之演进。过去那种“通/断”二元判断的简单监控已跟不上发展,取而代之的是以响应时间、错误率、流量、饱和度为核心的立体化可观测体系,不仅关注“是否运行”,更关注“运行得如何”。
构建的复杂分布式系统,不仅要“能跑通”,更要“跑得快、跑得稳”,在可预期的时间窗口内交付结果,为用户(以及依赖它的其他系统)提供一致且可靠的服务体验。
所以现在SLO(服务水平目标)的价值会越来越重要。可能国内不常讲SLO这个词儿,但和另一个“可观测”的词儿,背后的思想目标是一致的。这不是说在盲目追求技术名词潮流,反而是因为它更能反映“高质量服务”的真实含义:企业也能据此设定明确的性能基准,持续优化达成情况。
在这个时代,“在线”已远远不够——快速、稳定、可预测,才是服务合格的真正底线。毕竟,慢,本身就是一种故障。
其他观点
- 运维的杂事儿(Toil)因为AI的接入,反而呈现变多的趋势。
- 尽管AI被寄予厚望,但实际数据显示工程师花在重复性、手动性任务上的时间反而增加。
- 可能原因:AI系统本身带来新的运维负担(如模型维护、GPU集群管理),或节省的时间被填入更多琐事。
- 需求上线deadline迫近与系统可靠性的取舍
- 越是面临上线压力的项目,越容易频繁降低可靠性的优先级。
- 虽然多数公司声称OKR清晰、重视可靠性,但在实践中仍常被迫“牺牲可靠性保交付”。
- 单一监控面板,还是多工具之痛
- 多数企业使用2–10种可观测性工具,这并非问题,关键在于价值是否大于成本
- “工具泛滥”不是数量问题,而是是否获得足够、可操作的观测数据;盲目追求“一个面板”可能适得其反。
- 通往精通还是痛苦的再学习之路
- 技术培训(尤其是AI相关)需求普遍,但缺乏时间是最大障碍。
- 管理层与一线工程师在学习偏好(如线上 vs 线下)上存在分歧,需更灵活的培训策略。
- 事故不是会不会发生,而是何时发生
- 事故频发(40%受访者每月处理1–5起),已成为常态。
- 事故后的心理压力、支持不足、复盘机制缺失等问题同样值得关注。
- 承认差距,才能弥补差距
- 指出 技术团队与业务管理层之间存在认知鸿沟:对可靠性实践的理解和评价存在显著差异。
- 呼吁建立透明沟通机制,确保可靠性目标与业务成果对齐。
后续看情况展开聊聊,关注公众号“现代技能栈”,回复“SRE2025” ,可获取行业报告原文。